
Finding unmatched braces (brackets)
By Bob Mesibov, published 13/08/2016 in Tutorials
Recently I was checking for unmatched braces in a big text file with nearly half a million lines (300+ MB). Was there a closing brace for every opening brace?
The text file was called 'beetle' and was actually a tab-separated table with each line divided into 77 fields. What I wanted to do was find any lines in which unmatched braces appeared within fields. Here's the command I used:
awk -F"\t" '{for (i=1;i<=NF;i++) if (split($i,a,"(") != split($i,b,")")) {print NR": "$0; next}}' beetle > unmatchedThe command took 1 minute 13 seconds to execute, which isn't bad for an operation that checked 36,036,077 data fields (with an Intel i3 dual core processor and 4 GB of RAM).

To explain how the command works, I'll use a small tab-separated table called 'demo' with 3 fields:

AWK has a 'split' function which takes 3 or 4 arguments. The first argument is the string to be split and the third is the character or characters on which to do the splitting. The second argument is the name of an array into which the split-out bits will be stored, and the fourth (optional) argument is an array containing the separators. What 'split' returns is the number of split-out items in the array.
In the command below, each line in 'demo' is split using '(' as a separator and the number of split-out items is printed for each line:
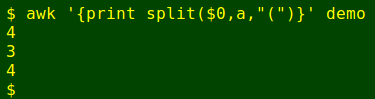
Note that AWK found 4 split-out items in the first line, namely a, aaa)[tab]bbbb[tab], cccc plus an empty item separated from the rest by '('. In other words, the number of items put into an array by 'split' will always be just 1 more than the number of separators. Note also that AWK emptied the array 'a' before splitting the next line.
Repeating the command with ')' as separator and loading an array 'b', we get:
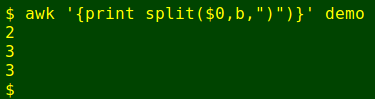
Now to see whether the number of opening and closing braces is the same in each line. In the following command, AWK is asked to check whether the same number of split-out items is found for each brace type, and if not, then the line number is printed followed by the whole line:

That worked well, but note that line 2 only has matching braces as a whole line. Fields 2 and 3 in line 2 both have unmatched braces. To look within fields, the full command above uses a for loop to do the checking on each field in turn. If unmatched braces are found in any field, AWK prints out the line number and the whole line, then jumps to the next line following the 'next' instruction.
The full command isn't perfect because it won't find a line in which a field has braces matched 'backwards', like this: aa)aaa(a. I checked that possibility with another AWK command using a rather complicated regex. Here the command is looking at 'demo_new' with an added line including 'backwards' braces:
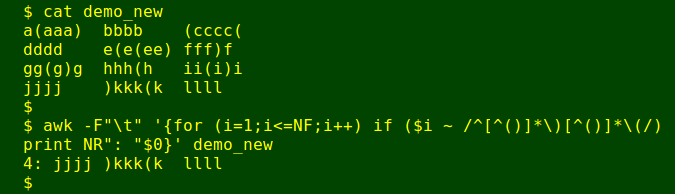
There were no such lines in 'beetle', but the command at the beginning of this article did find 35 lines in 'beetle' containing fields with unmatched braces. I checked the 35 lines individually to see what the problem was (typo? truncated string?), then fixed each one with sed. For example:
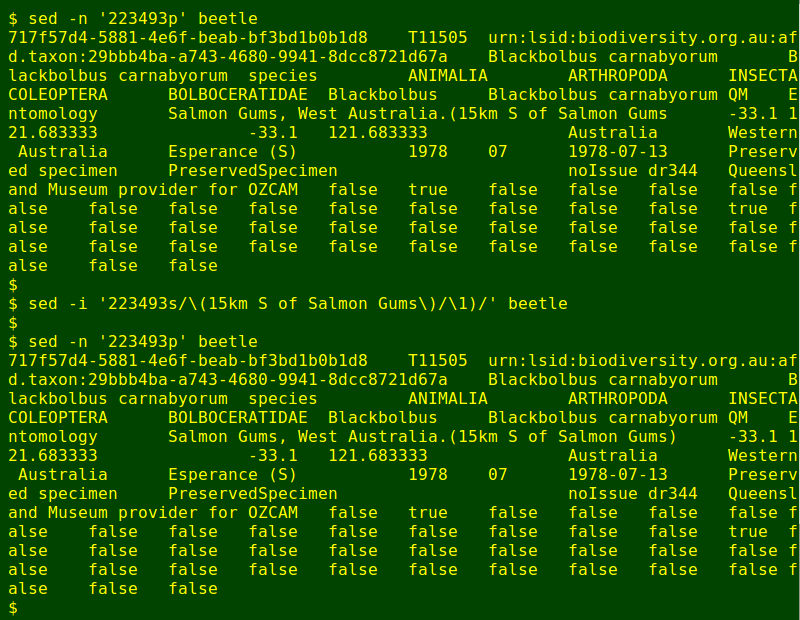
I repeated this process for unmatched square brackets ([]), curly brackets ({}) and greater-than/less-than arrows (<>). A fiddly proofreading job, made easier on this monster file with AWK!