Joining Tables on the Command-Line
By Bob Mesibov, published 02/09/2014 in Tutorials
This article compares 3 different ways to join tables on a common field. All 3 work OK on small tables, but there's a big difference in speed when the tables to be joined are large, as shown below.
Table joining isn't something you need to do if you store data in a simple, flat-file database like a spreadsheet. With flat-file data storage, all the information for a particular record (row) is found within that record. If the entries in a particular field are the same from record to record, so be it — and there's nothing wrong with keeping data this way.
An alternative approach is used in relational databases and for other purposes. Data items likely to be duplicated are kept in a separate table, where each item is unique and has its own identifying number or other code. In the main table, that unique identifier appears as a placeholder for the full data item.
Here's an example, using international Test centuries scored by the great Sri Lankan batsman Mahela Jayawardene. The file jaya1 is a tab-separated table that lists Mahela's totals in chronological order, with a serial number for the record, the number of runs scored per Test, the opposing side and the date:
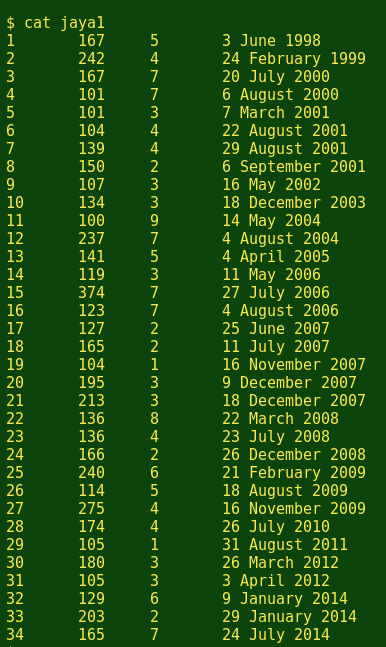
In this 'runs table', the third field contains placeholder numbers which represent opposing cricket sides. The corresponding teams are listed with unique numbers in the 'teams table', file jaya2:

To get the placeholders in the 'runs table' replaced by their appropriate team countries from the 'teams table', we need to do some table joining.
Method 1: GNU/Linux join
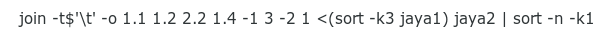
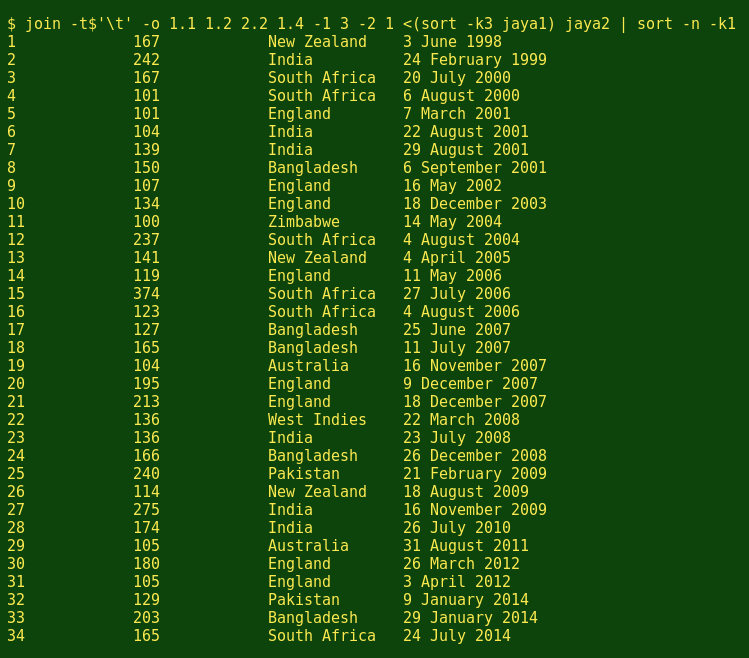
The GNU/Linux join command joins 2 tables at a time on a common field, but it requires that the relevant fields be sorted. Field 1 in jaya2 is already sorted, but field 3 in jaya1 isn't. The command above does the jaya1 sorting as a separate process and feeds the result to join with a process substitution, <(sort -k3 jaya1), where -k3 tells sort to sort jaya1 on field 3.
Now for the join options. The option -t$'\t' tells join that the fields in the two tables are tab-separated. The next option, -o 1.1 1.2 2.2 1.4, tells join that the output should contain field 1 from table 1 (1.1), field 2 from table 1 (1.2), field 2 from table 2 (2.2) and field 4 from table 1(1.4), in that order. The statement -1 3 -2 1 tells join to find and print the lines in the 2 tables where field 3 in table 1 matches field 1 in table 2.
The join output is still sorted on field 3 of table 1. To get the output back in the original 'runs table' order, the output is piped through a numerical sort (-n) on field 1 (-k1).
Method 2: A for loop with AWK

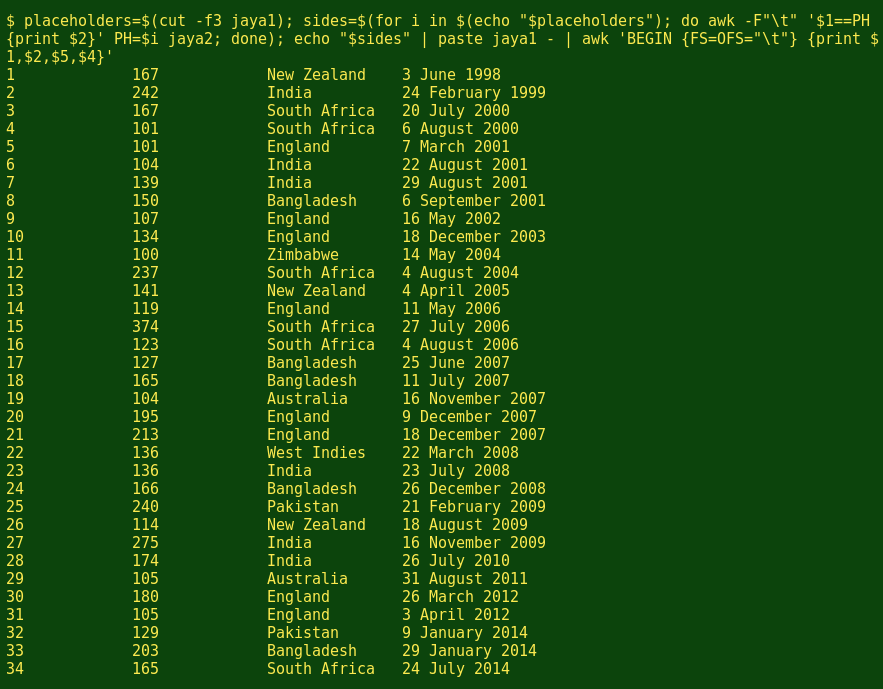
This method's more complicated, but nicely logical. First, the cut command pulls out the placeholder field (-f3) from the 'runs table' and store the field in a variable, placeholders.
The for loop selects items from placeholders one by one and feeds them to AWK. AWK searches jaya2 line by line, each time looking for an item in jaya2 field 1 that matches the currently selected item from placeholders. When a match is found, AWK prints the contents of jaya2 field 2. (In this command, AWK is acting a lot like a spreadsheet LOOKUP function.) The output of the for loop is stored in a new variable, sides.
Next, the echo and paste commands add the lines in sides to the ends of the corresponding lines in the 'runs table', separating the two with a tab, which is the paste default separator. The paste command normally joins 2 files; here it joins a file and standard input, represented by '-'.
Finally, the result of the paste is piped to AWK, which prints the fields we want in the order we want.
Method 3: An AWK array
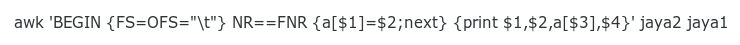
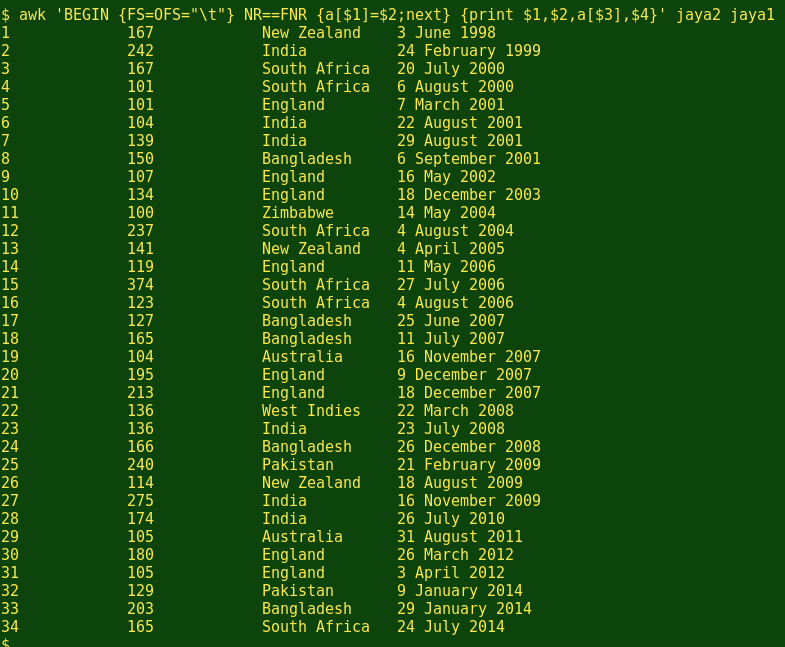
This is one command, but in 2 parts. AWK first goes line by line through the 'lookup' file (jaya2) and creates an array 'a' whose key is from field 1 and whose value is from field 2. In other words, AWK copies the 'lookup' file as a kind of hash table and stores it in memory.
Having finished memorising the 'lookup file' (NR==FNR), AWK next processes the second file (jaya1) line by line, printing the fields requested, namely 1, 2 and 4. It also prints the array, but here the key to the array comes from field 3 (a[$3]). When the field 3 item matches one of the memorised keys, AWK prints the value associated with that key.
Speed testing
The 3 methods work quickly on the small tables jaya1 and jaya2, so I'll try some heavier-duty processing with a couple of my tab-separated biodiversity data tables. The 'main' table contains 11 fields and 2347 lines and the placeholder field is field 3. The 'lookup' table contains 19 fields and 9699 lines, and field 1 in 'lookup' corresponds to placeholder field 3 in 'main'. I want to add fields 10 and 11 from 'lookup' to field 2 in 'main'; it doesn't matter how the output table is sorted. The commands are:

And here's how long each took to execute, as measured by the time command and with method 2 saved as a BASH script (M2.sh) to avoid confusing time with method 2's separate commands.
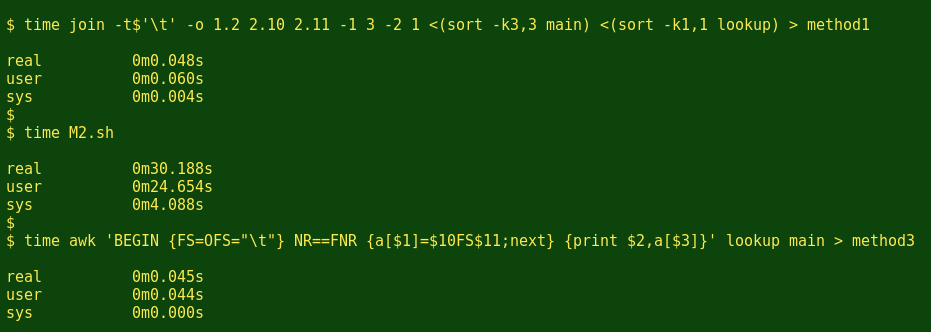
That's a pretty clear result: less than 50 milliseconds for methods 1 and 3, and 30 whole seconds for method 2. The 3 output files each contains the same 2347 lines, but the method1 table from the join command doesn't preserve the original sort order of main.
Conclusion: use method 1 or method 3.