Shifty dates in Microsoft Excel
By Bob Mesibov, published 03/10/2017 in Tutorials
Microsoft has used two different starting points on the calendar for calculating dates in different versions of their Excel spreadsheet program. Really.
Microsoft explains the difference here. One version used 1 January 1900 for serial day numbering, the other used 1 January 1904.
Of course, up to date versions of Microsoft Excel can handle this difference in older files easily, just like up to date versions of Microsoft Windows are completely problem-free and totally, absolutely secure.
But there are databases around the world which imported data from Excel and have lurking within them this Excel date shift issue. A date might be correct, or it might be off by 4 years and 1 day. If there was database or file merging in the past, there might be two versions of the same record. The two records would be identical except that their dates would differ by 1462 days.
How could you find those Excel duplicates?
I recently had this problem with a file containing more than 1.1 million records. In simplified form, the records looked like the ones in the table below. These are records of Tasmanian eucalypt species at particular places on particular days, recorded by the fictititous botanist Fred Bloggs. There are 6 tab-separated fields in the table: unique ID number, name of the recorder, date in ISO8601 format, latitude in decimal degrees, longitude in decimal degrees and eucalypt species name.
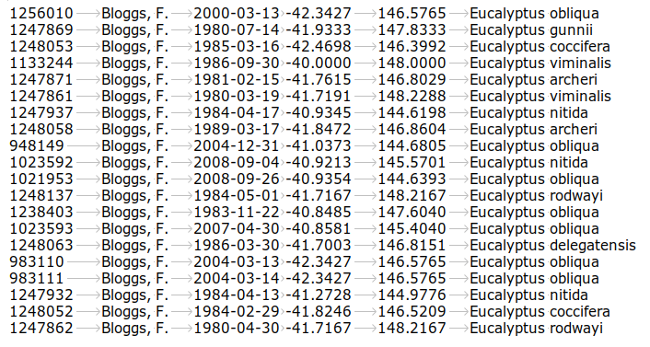
In this set of 20 records there are two pairs of Excel date duplicates. Can you spot them? Good on you if you can, but how would you go spotting an unknown number of possible duplicates among a million records?
OK, let's open a terminal and do some command-line magic.
Welcome to our epoch
The first step is to add to each record the number of seconds in UNIX time for each date, i.e. the number of seconds since UNIX time began at 0 hours, 0 minutes, 0 seconds on 1 January 1970.
There are two straightforward ways to do this. One is to paste together the original table (demo, shown above) and the result of cutting out the date field and processing it with date to convert ISO8601 dates to UNIX seconds, as shown below. The -f option for date tells the command to work line by line through the indicated file.
paste demo <(date -f <(cut -f3 demo) +%s) > demoA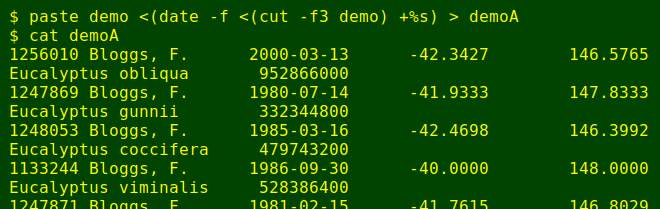
The second method uses AWK and looks more complicated, but it's considerably faster on large files:
awk -F"\t" '{split($3,t,"-"); print $0 FS mktime(t[1]" " t[2]" "t[3]" 0 0 0")}' demo > demoA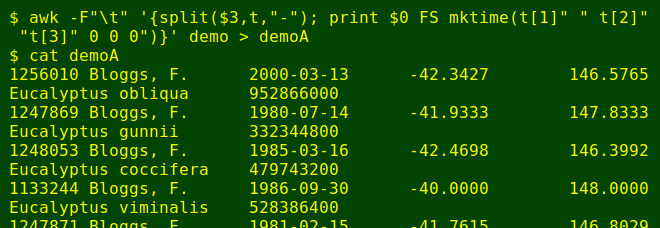
The key bit here is AWK's built-in "mktime" function. Like date -d [date] +%s, "mktime" on a Linux system will convert a date into UNIX seconds. What goes into the parentheses after "mktime" is YYYY MM DD HH MM SS. To get YYYY MM DD from the hyphenated YYYY-MM-DD in field 3 of demo, I use another AWK built-in, "split". Here "split" takes field 3, splits it into the 3 bits separated by hyphens, and puts each of the bits into an array "t". The elements of the array can be called up later: t[1] is YYYY, t[2] is MM and t[3] is DD.
After splitting field 3, AWK's next job is to print. First it prints the whole line ($0), then the field separator FS (a tab in this table), then the UNIX seconds as calculated by "mktime". When AWK moves to the next line, the "split" command starts afresh and array "t" gets the pieces from the current line.
Gather the start and end dates
If there are two records in the table differing only in date (by 1462 days, and of course also by the unique ID number), then the "end date" member of the pair can be found with a trick. First I'll pull out of demoA a sorted, uniquified list of recorder, latitude, longitude, species and UNIX time:
cut -f2,4,5,6,7 demoA | sort | uniq > demoB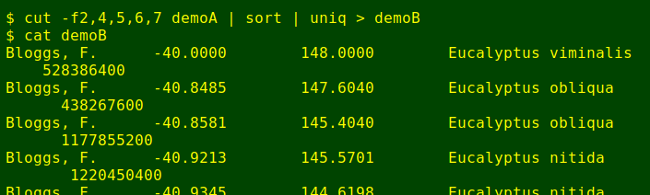
Next, I'll add 126316800 seconds to the UNIX time in all the records. That's 1462 days times 86400 seconds per day. If an abbreviated record with added seconds is the same as one of the original records, that's the "end date" version of an existing "start date" record. I can find these with the comm -12 command, which prints lines common to the two files being compared:
comm -12 <(sort demoB) <(awk 'BEGIN {FS=OFS="\t"} {print $1,$2,$3,$4,$5+126316800}' demoB | sort) > demoC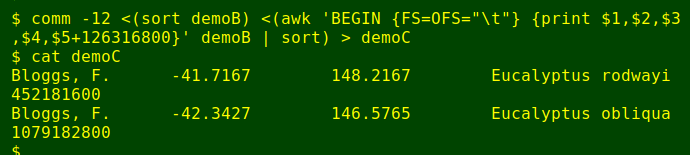
The "start date" versions of these "end date" records will have 126316800 fewer seconds in their UNIX time field. If I concatenate these "start date" and "end date" versions, I get a list of Excel duplicate pairs, but without the unique ID for the record:
cat demoC <(awk 'BEGIN {FS=OFS="\t"} {print $1,$2,$3,$4,$5-126316800}' demoC) > demoD
Last steps
Now to find those shifted-date pairs in demoA and present them as they looked in the original records, with their unique ID number restored. The most straightforward way would be to search demoA with grep -f, where the "-f" option tells grep to use the contents of a file, in this case demoD, as its search pattern. Unfortunately grep doesn't like the tab characters that separate the fields in demoD. I'll therefore modify demoD with AWK to make it more grep-friendly:
awk 'BEGIN {FS="\t";OFS="[[:space:]]"} {$1=$1} 1' demoDThis command replaces tab characters as field separators (FS) with the string "[[:space:]]", which is a POSIX class character that grep understands as whitespace or tab. The "$1=$1" bit forces AWK to reset the field separators, and the trailing "1" tells AWK to process every line.
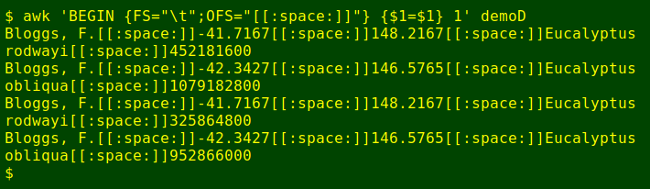
Not quite ready, because in demoA there's that ISO8601 date string between the recorder field and the latitude field. No problem for AWK, I'll just prefix field 2 (the latitude field) with a string representing some unknown characters (the ISO8601 string) plus that "[[:space:]]" string:
awk 'BEGIN {FS="\t";OFS="[[:space:]]"} {$2=".*[[:space:]]"$2} 1' demoD > demoE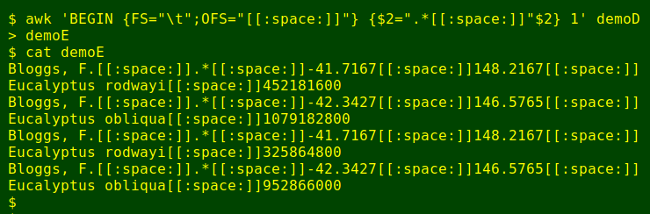
demoE is now the file containing the parts-of-lines that I want grep to find in demoA. I'll take what it finds, sort the result, cut off those appended UNIX seconds and sed a space between pairs of lines:
grep -f demoE demoA | sort -t $'\t' -k2 | cut -f7 --complement | sed n\;G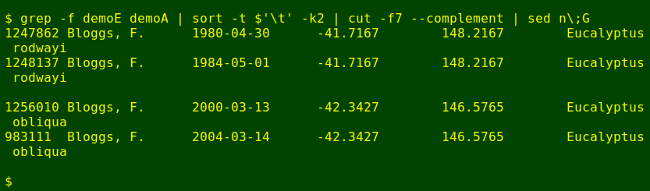
And there they are: the 2 possible Excel date duplicate pairs, separated within a pair by 4 years and a day, and neatly presented.
Cautions and afterthoughts
I wrote "possible Excel date duplicate pairs" for a reason. Those pairs might be the same record with 2 different Excel datings, true, but it's also possible that Fred Bloggs visited the same spot and recorded the same eucalypt species on two dates 1462 days apart. Best to check with Mr Bloggs!
Note also that for clarity's sake I split the procedure explained above into pieces with 5 different temp files (demoA, demoB, etc), but some of the steps are easily combined, and that's what I did with the 1.1 million-record file. I tried to nut out some AWK-only solutions for this job but failed, and the ones I fiddled with required a lot of computing grunt. The comm trick in the procedure above is a nice shortcut.
Actually, I didn't use the recorder field in the procedure, because some known Excel date duplicates in the big file had two string variants of the recorder name, like "Bloggs, F." in the start-date record and "Fred Bloggs" in the end-date record. For the 1.1 million-record job I pulled out potential duplicates based on other fields, then manually deleted pairs with clearly different recorders, something the command line couldn't help me with.