Tips on Tables
By Bob Mesibov, published 04/06/2014 in Tutorials
Big data or small data, a lot of it comes these days as plain text arranged in rows and columns. Here are a few tips on working with tables of text, both in text editors and on the command line.
CSV isn't what it seems. Text tables are often exported from databases and spreadsheets as comma-separated value, or CSV files. That sounds like each data item in a row is separated from its neighbours by a comma, but it ain't that simple. Sometimes each item is double-quoted before separating with a comma, so as to avoid confusion with commas within data items. Sometimes data items containing spaces are double-quoted, sometimes not. Sometimes every data item is double-quoted.
Below are are 3 different CSV versions of a header row and a data item row. All 3 look exactly the same when pasted into a spreadsheet application (after specifying 'comma' as column delimiter), but as text they're quite different.

My own preference is for data items separated by tabs, i.e. tables in tab-separated value format, or TSV. No superfluous double quotes needed, just a tab, and as shown below, TSV files can be displayed very neatly in a text editor or terminal. For non-text applications that demand a filename suffix, try .tsv or .tab, or just use .csv — spreadsheets like Gnumeric will open a TSV properly even if it's called a CSV.
What if the CSV has data items with a tab inside, and you want to make the table into a TSV? Those hidden tabs are going to seriously mess up the column arrangement, so it's worth checking for any existing tabs and replacing them before you convert from CSV to TSV. A simple way to find tabs on the command line is shown here:
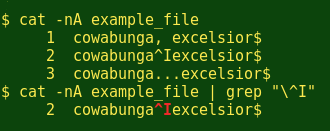
The command cat -nA prints the file with every line numbered (-n option) and with non-printing characters made visible (-A option). The non-printing tab character will appear as '^I', so if you grep for that, escaping the ^ with a backslash, you'll be shown any tabs lurking in the table and where they're located.
(The grepped '^I' is in red in the screenshot because my ~/.bashrc file contains the alias grep='grep --color=auto'. See this 'Linuxaria' article for a good introduction to colorising grep. )
How to convert a CSV to a TSV? The easiest way is to import the CSV into Gnumeric or LibreOffice Calc, select all the cells, copy them and paste them into a text editor. By default, the data items in each row will be separated by tabs:
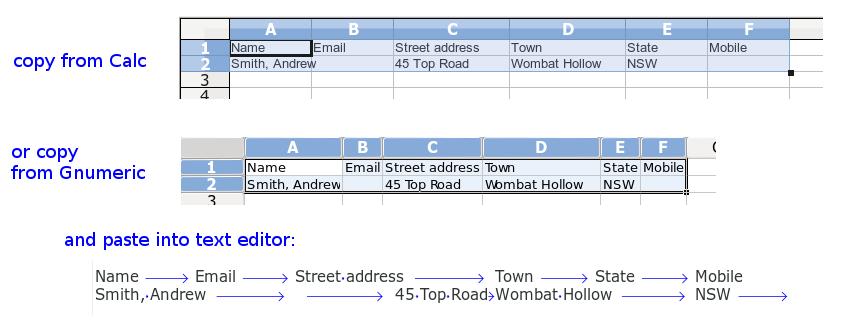
(Tabs are normally invisible. They've been made visible here in gedit text editor with the 'Draw Spaces' plugin.)
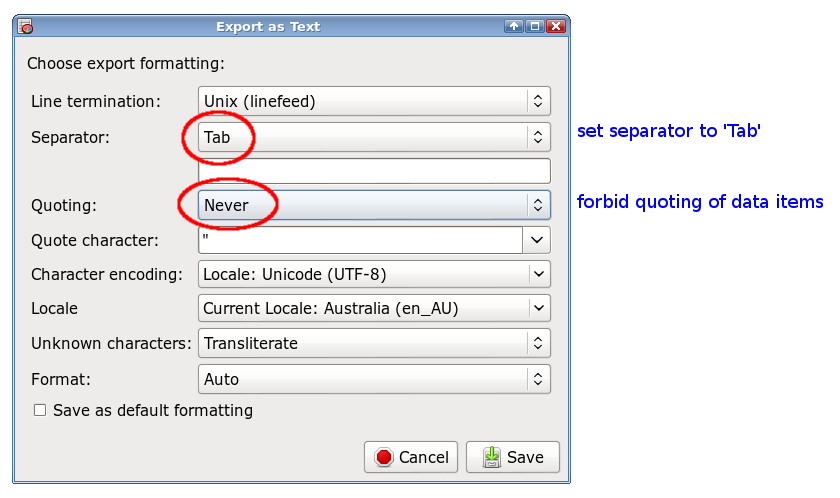
Another method using a spreadsheet is to import the CSV, then save it as a tab-separated text file. The details will be different for different spreadsheet applications, but if you use Gnumeric, be sure to tell Gnumeric not to quote cell contents, or you'll wind up with unnecessary double quotes:
If the CSV is huge, you may have trouble loading it into a spreadsheet, in which case the command line is your friend. I use sed to do CSV > TSV, but the command will vary depending on what needs to be replaced or deleted. Here are 2 examples using abbreviated lines from CSVs I've worked with:

Displaying tabbed columns neatly in a text editor
If you're staring at a TSV in a text editor or a terminal, it helps to get the columns lined up. Most text editors allow you to change the size of a tab from the usual 8 characters to some larger number of characters. The example below shows gedit displaying part of a table with the tab set to the default 8 characters (top) and the gedit maximum, 24 characters (bottom):
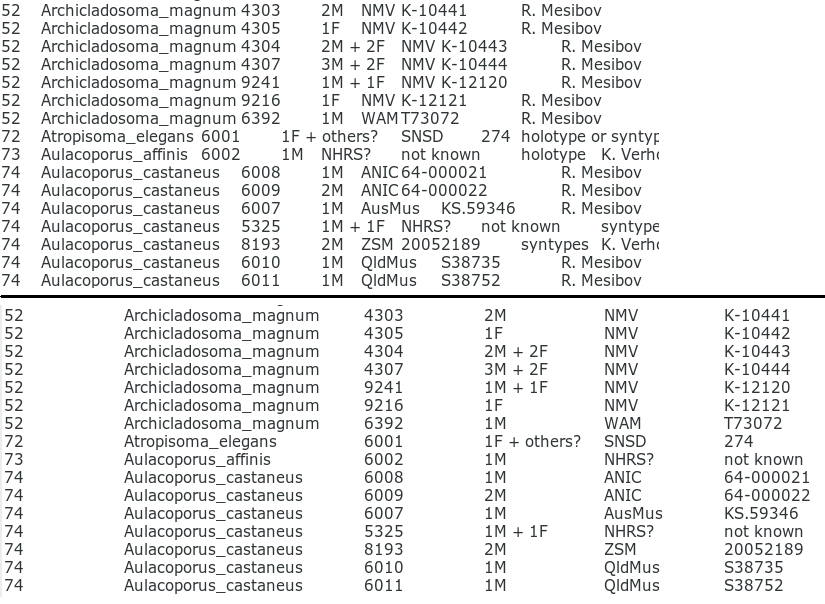
If column selection (or 'block selection', or 'rectangular selection') is available in your text editor, having the tabbed columns neatly separated will make the selecting easier. Below is an example of column selection in Geany text editor. The selection (grey highlight) covers 2 columns and 6 rows (12 data items) and was made by mousing with Shift and Ctrl held down.
Displaying tabbed columns neatly in a terminal
You can set the tab spacing in a terminal with the tabs command, as shown below. The new spacing will only be used in the current terminal session, and will revert to 8 characters next time you open a terminal. To revert to that default during the current session, just enter tabs -8.
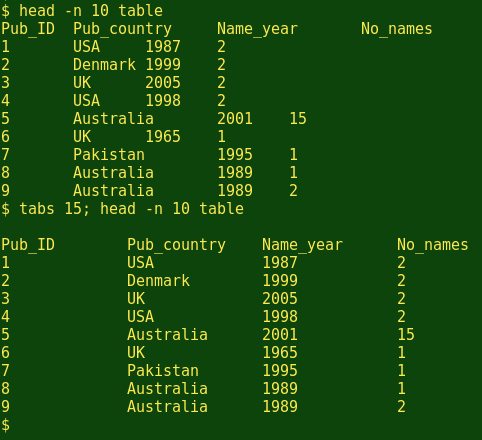
(The tabs command also allows you to set different tab widths between columns. See the tabs man page under 'Explicit Lists'.)
AWK and column numbers
AWK is by far the best table-wrangler on the command line, but I have one small problem with it. Columns (fields, in AWK-speak) are represented in AWK coding with a number preceded by a dollar sign. The first column is $1, the second is $2, and so on (the whole line is $0).
Alas, but my memory isn't good enough to remember which column is which. To help me out, I've written the following function for my TSVs and put it in my ~/.bashrc file:

The function assumes that the first line in the TSV is a header with column names separated by tabs. This line is pulled out of the TSV by head -n 1. The tabs are then replaced by the tr command with newlines, so that the fields are simply listed, one after the other. The list is numbered with cat -n, then printed to the terminal screen in 2 columns with pr -t -2 (the -t option suppresses header and footer printing by pr). Here's how the function works with a 22-column table ('NAI50') I recently worked on:

Before coding an AWK command for a big table, I always run 'fields'. Very handy!