
ODT to TXT, but keep the line numbering
By Bob Mesibov, published 30/06/2014 in Tutorials
The title explains what this article is about. If you save an .odt file as text, or copy/paste the contents as a text file, or run odt2txt or the unoconv utility, you lose the apparent line structure of the original, and with it the line numbering. But there is a way...
Losing apparent line structure
Here's a sample text, sample.odt, as seen in LibreOffice Writer with line numbering turned on. I've used a 12-point proportional font, and Writer has fitted the words to the lines as you see them, as best it can:

If I save or copy or convert the sample to plain text, the apparent line structure in the .odt disappears and the text editor or terminal likewise fits the words to the lines as best as the program can:


A hackish workaround
How to preserve the apparent line structure through the ODT to TXT transition? Well, I could save sample.odt as PDF, a format which does preserves line structure, then extract the text from the PDF. To do this I can use the unoconv and pdftotext utilities:

By default, unoconv converts an .odt file to a .pdf file with the same name. On my Xfce machine, unoconv also throws up an ignorable warning message; this comes from a years-old Gnome bug that hasn't been squashed yet.
pdftotext with the -layout option keeps the original layout, saves to a .txt file with the same name as the .pdf, and even adds line numbers. The resulting sample.txt is almost what I wanted:


That sample.txt, however, is a bit different from the original. The tabs at the start of each paragraph have been converted to multiple whitespaces, and there's an added line at the end with a non-printing character. I can remove the last line, the added line numbers and the extra whitespace with a couple of commands to make sample_fixed.txt:
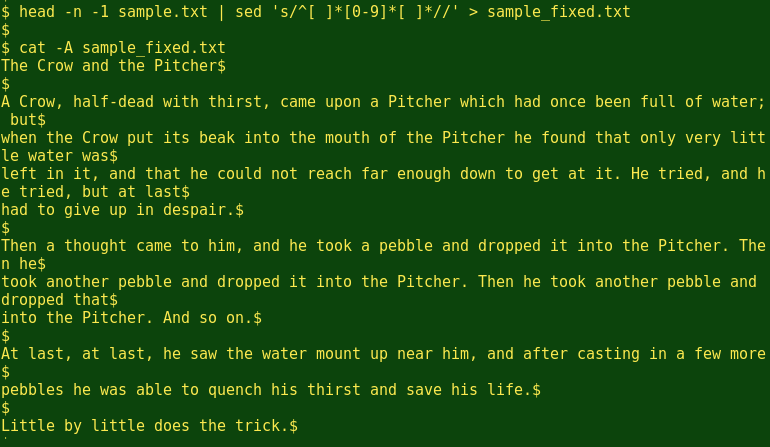

[The head command prints the 'head' of the file except the one last line (-1). The sed command deletes leading whitespace, line number and following whitespace.]
However, although sample_fixed.txt has the same apparent line structure and numbering as in the original .odt, it's lost the tabs that opened each paragraph. It's also lost some deliberate spacing mistakes, namely a double-spaced gap in lines 4 and 5, and a tab instead of whitespace in line 12 (visible in the first illustration above, if you've got sharp eyes). These have been replaced with single whitespaces by pdftotext.
Please explain
So why did I put in those deliberate, now-lost mistakes?
Well, I write long .odt documents in LibreOffice Writer. Unfortunately I'm careless and I put tabs and multiple whitespaces in places where they don't belong. By using Writer's Find function I can search for and highlight these mistakes. However, so far as I know there's no way to filter these results, so that I can see all of the lines needing to be edited in one place, together with their line numbers.
That's easy to do, however, with a text file on the command line. I'll put those deliberate mistakes back into sample_fixed.txt and call the new file sample_restored.txt. Then I'll then run a couple of commands which find the lines with mistakes, print the lines and their numbers and show the multiple spaces and tab in pretty colors:
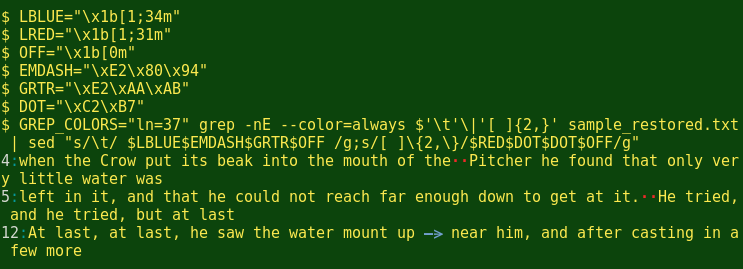
[grep here is looking for either the tab character (\t) or 2 or more whitespace characters in a row ([ ]{2,}). It prints the line numbers of the lines it finds (-n) and colors those numbers white (GREP_COLORS="ln=37"). grep passes on its finds to sed with color intact because the command includes the --color=always option. sed does the 'make more visible' job. It replaces any tabs with blue-coloured em dash and greater-than symbols, which together make a prominent arrow, and puts a space fore and aft of the arrow. sed then replaces 2 or more whitespace characters in a row with 2 red dots in a row.]
These commands and variables could easily be put into a script. If I could just find a way to convert .odt to .txt which preserves both the apparent line structure and the multiple whitespaces and tabs, then I could run a script on an .odt file and print only the lines with multiple whitespaces and tabs in a terminal, together with their line numbers in the original .odt. I could then decide which of those need changing, open the original .odt, go to the relevant line numbers and do the editing.
Two halves of the problem solved, but the two halves don't fit together. I'm still working on this hack and suggestions are welcome!