
Grouping things with AWK
By Bob Mesibov, published 22/01/2015 in Tutorials
In this article I explain one way to group data items with AWK arrays. The code is a little mysterious but the results are impressive, especially in my second example!
Case 1: Cricket stats
The table 'runs' is tab-separated and lists the 86 national team cricket players who scored (or have so far scored) at least 5000 runs in their careers, together with their countries and their runs totals, in descending order. Here are the first 10 lines of the table:

What I'd like from this table is the results organised by country and player, like this:

and here's the code that does it:
awk -F"\t" 'NR>1 {a[$2]=a[$2] ? a[$2]", "$1" ("$3")" : $1" ("$3")"} END {for (i in a) {print i": "a[i]}}' runs | sort | sed G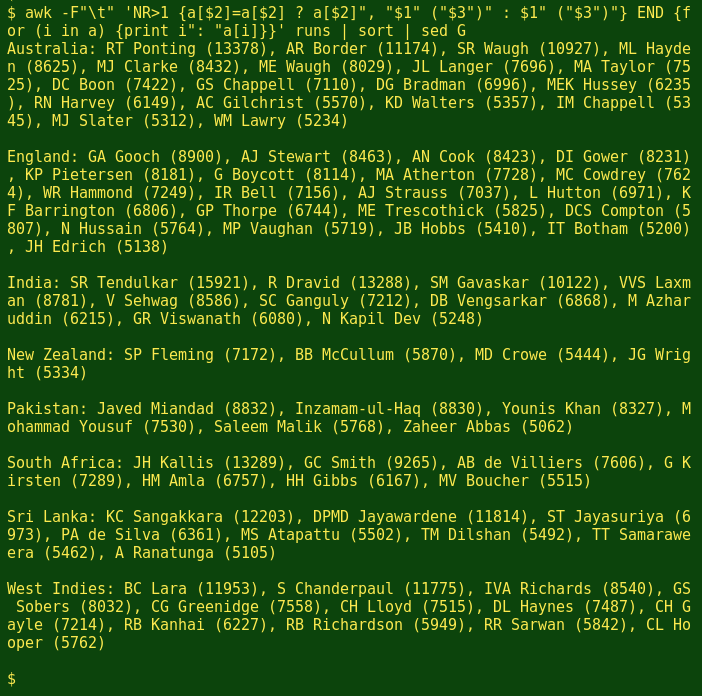
Like I said, the code's a little mysterious — until you examine it piece by piece, to see how it's built.
How an AWK array works
An AWK array is a set of index-value pairs. For every unique index item, there's an associated value. Both the index and the value can be plain, ordinary strings.
For example, I can build an AWK array where the index item comes from the country field in the runs table (second field, $2). All I have to do is give AWK a name for the array and tell it where to find the index. If I name the array 'a', AWK will build a 'countries' array when I declare 'a[$2]'. In the following command, I first tell AWK with -F"\t" that the runs table has fields separated by the tab character, \t. I then get AWK to build an array from the country field with {a[$2]}. I can see what's in the array with an 'END' statement that tells AWK: After you finish building the array 'a', go through it index item by index item ('for (i in a)') and print each one.:
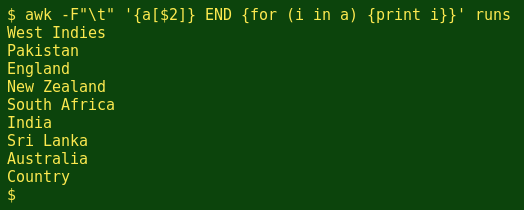
Two things to note here. The first is that AWK has included the header-line entry ('Country') as an index item. I can get AWK to ignore the header line, which in AWK-speak is record number 1 (NR is 1), by including the condition 'NR>1' when the array is built:
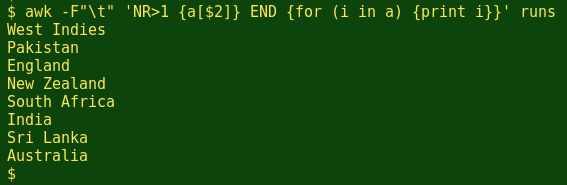
The next thing to note is that the array doesn't contain the countries in alphabetical order, or for that matter in the order they appear in the runs table (see first illustration above). AWK arrays aren't ordered. To put the countries in alphabetical order, I can pipe the output to sort:
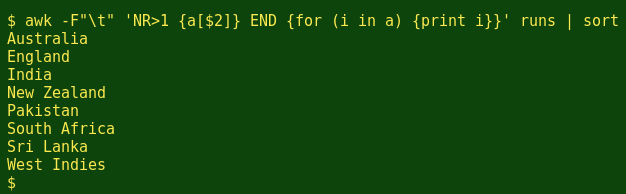
I can also tell AWK to print the value associated with each index item, like this:
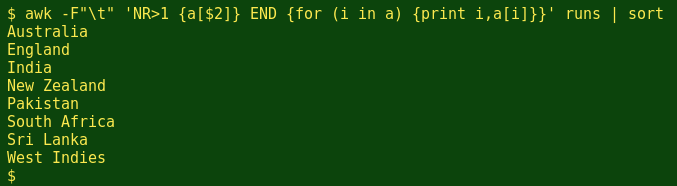
Why did nothing happen? Because I haven't told AWK how to get a value for each index! OK, I'll tell AWK to get the value from field 3, the runs numbers, and to increment these, with a[$2]+=$3. In other words, AWK will add up the runs numbers for each country as it goes through the table:
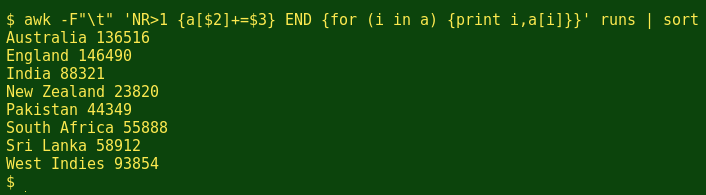
Nicely done, but a pretty meaningless statistic. I could add an explanation to that print command in the END statement with print "Batters from "i" totalled "a[i]" runs in the runs table", but that's really just showing off AWK's 'print' command:
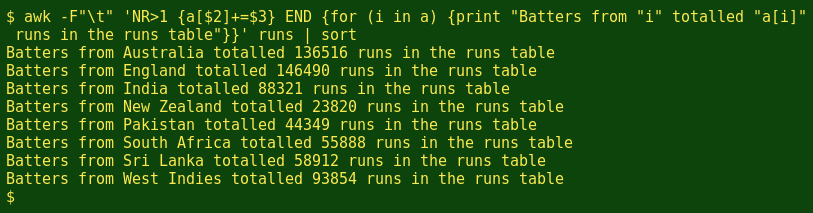
Tweaking the array
What I actually want for each index item (each country) is the batter's name (field 1, $1) followed by a whitespace and the career runs total (field 3, $3) in brackets. To do that I could tell AWK that items in the array a[$2] will have the value $1" ("$3")", and I can make the output clearer by getting AWK to print [country]: [batter] (runs)]
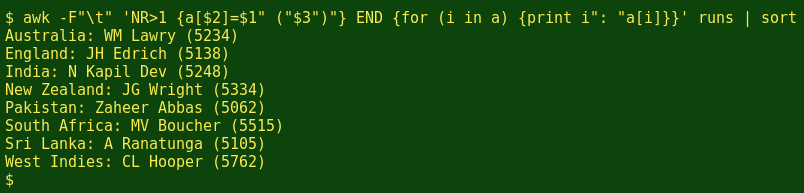
Well, that sort of worked. But what I got was only the last player for each country in the runs table, with that last player's career total. I need clearer instructions for AWK, of this kind: As you go through the runs table, if you haven't seen that country before, add it to the index list in the array and assign to it the value $1" ("$3")". If you already have that country in the array, then to the value of that index item add the value you have so far, plus a comma and a whitespace, plus the $1" ("$3")" for the new record, or in other words a[$2]", "$1" ("$3")".
This 'if/else' statement is neatly abbreviated with ternary operator syntax, which looks like this:
[condition to be tested for] ? [if condition met, do this] : [if condition not met, do this]In this particular case, the if/else statement will say:
a[$2]=a[$2] ? a[$2]", "$1" ("$3")" : $1" ("$3")"where the condition to be tested for (a[$2]=a[$2]) is whether the indexable country on the current line is already in the array. And it works very nicely (see above, third illustration). The final touch is to pipe the result to the sed command with the 'G' option, which double-spaces the result for clarity. I can also print the array values for one country alone, for example India, just by specifying 'India' as the index item to be selected:

Case 2: Species by genus
I recently needed just this kind of AWK grouping to deal with a biological species list I named 'gensp'. I built the list from a freely available Catalogue of Life file. The 'gensp' list contains 1,073,783 unique species names in the form Genus[tab]species, sorted alphabetically first by genus, then by species. Here's part of that million-name list:
The list contains 112,020 unique genus names. For each genus I wanted a comma-separated string of species, like this:

I used the AWK command
awk '{a[$1]=a[$1] ? a[$1]","$2 : $2} END {for (i in a) {print i":"a[i]}}' gensp | sort > list_by_genusand got my list, but what's seriously impressive is the time AWK took to process the million-odd records this way, before the final sort:
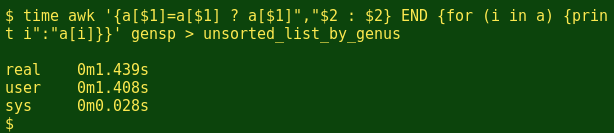
Wow. Less than 1.5 seconds on a desktop with an Intel i3 dual core processor and 4 GB of RAM, and the sort command only needed another 0.7 seconds to finish the job. For efficient data processing, AWK's hard to beat.