Some baby name problems
By Bob Mesibov, published 01/05/2015 in Tutorials
No, these aren't homework problems from a computer science class. They're interesting head-scratchers based on a data-analysis project I worked on recently, with the data 'reimagined' here for simplicity but with the underlying problems intact.
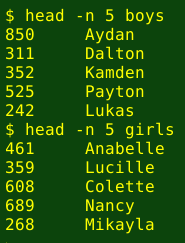
We'll start with boys and girls, which are text files each listing 1000 names for babies, plus their popularity in rank order from 1 to 1000. (I got the two lists from here.). The files are tab-separated and I've shuffled each of them with the shuf command. Here are two samples:
Problem 1
Find all the unisex names in the two lists (identical names for boys and girls) together with their rankings. List the results alphabetically by name with the gender flagged.
The solution I came up with was:
awk 'FNR==NR {b[$2]=$0;next} $2 in b {print "boy\t"b[$2];print "girl\t"$0}' boys girls | sort -k3 > unisex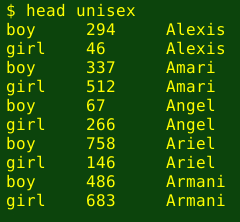
The command works by first building an AWK array 'b' from the boys file. Each element in the array is indexed with a boy's name and has the whole line (rank, name) as its value. AWK then looks through the girls file for any lines with a girl's name that also appears in the boy-name array 'b'. When such a line is found, AWK first prints 'boy' (tab) and the value of the matching array element, then 'girl' (tab) and the matching girl's rank and name. The output is sorted alphabetically on name.
With these particular boys and girls lists I found 69 unisex name pairs. Notice that I didn't have to specify a field separator for AWK, because there are no tabs or whitespaces within the fields, and AWK recognised the tabs between the fields as separators, as did sort.
An alternative solution without using AWK starts by flagging every line in boys and girls with the relevant gender. The two files are then concatenated and sorted on name. The output is fed to uniq with the '-f' option set to ignore the first two fields, and the '-D' option to print all name duplicates:
cat <(sed 's/^/boy\t/' boys) <(sed 's/^/girl\t/' girls) | sort -k3 | uniq -f2 -D > unisex_altThere's a curious 'gotcha' in this alternative solution. My data analysis files had whitespaces within fields, so I specified tabs as field separators for both AWK and sort. The uniq command doesn't have a way of specifying field separators, and the '-f2' option would give strange and unexpected results with those data analysis files.
Problem 2
Compare the unisex names by their rank popularity within genders. For example, are there any unisex names which have exactly the same rank as a girl's and as a boy's name? Which unisex names are very much more popular for girls than for boys, and vice versa?
For me, the easiest way to answer questions like these is to put both members of a unisex name pair on the same line, and get AWK to process the data. There are two simple ways to do the all-on-one-line arranging. The first is to modify the 'print' part of the AWK command used in Problem 1:
awk 'FNR==NR {b[$2]=$0;next} $2 in b {print "boy\t"b[$2]"\tgirl\t"$0}' boys girls | sort -k3 > one_line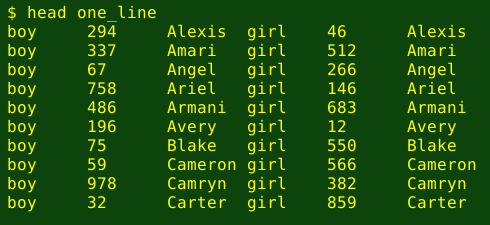
An alternative is to pull the boys' and girls' names from unisex as separate lists with grep, then paste them together (and note that paste uses a tab as default separator). This works because the name pairs are ordered, one after the other, and grep preserves that order:
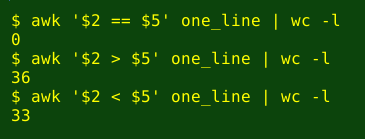
paste <(grep "boy" unisex) <(grep "girl" unisex) > one_line_altNow I can do comparisons with the one_line file. Are there any unisex names with the same rank? No. And there about as many unisex names with boy-rank lower than girl-rank (36) as unisex names with the opposite (33):
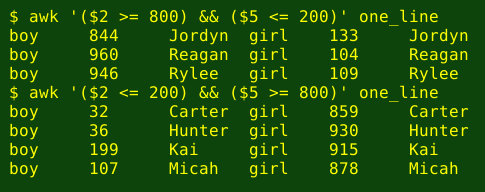
For the 'very much more popular' test I'll arbitrarily choose the highest 200 and lowest 200 in the rankings from 1 to 1000:
Problem 3
Which unisex name has the biggest rank difference? and the smallest?
awk '{$2-$5 >=0 ? rdiff=($2-$5) : rdiff=($5-$2)} {print rdiff"\t"$0}' one_line | sort -nr -k1 | sed -n '1p;$p'
Here AWK is used to print the rank difference (tab) and the full line, then the output is sent to sort for reverse numerical sorting on rank difference, and finally sed is used to print the first line (biggest rank difference) and last line (smallest rank difference).
Because rank difference ('rdiff') as calculated by AWK can be positive or negative, and because AWK doesn't have an absolute value function, I've used a test here. If boy-rank is a bigger number than girl-rank ($2-$5 >=0), 'rdiff' is defined as $2-$5; otherwise 'rdiff' is defined as $5-$2.