
Scripting an OCR text archiver for Trove
By Bob Mesibov, published 23/03/2014 in Tutorials
Trove is the National Library of Australia's online database. It contains almost 400 000 000 digital items, including Australian newspaper articles from 1803 to 1954.
Trove's newspaper portal is particularly useful. You can view an entire digitised newspaper page, or select (or search for) an individual article. Each article has been OCR'ed and the OCR text is presented in a separate box at the left of the page viewer (see screenshot below). Trove users can edit the OCR text, and users make tens of thousands of text corrections every day.
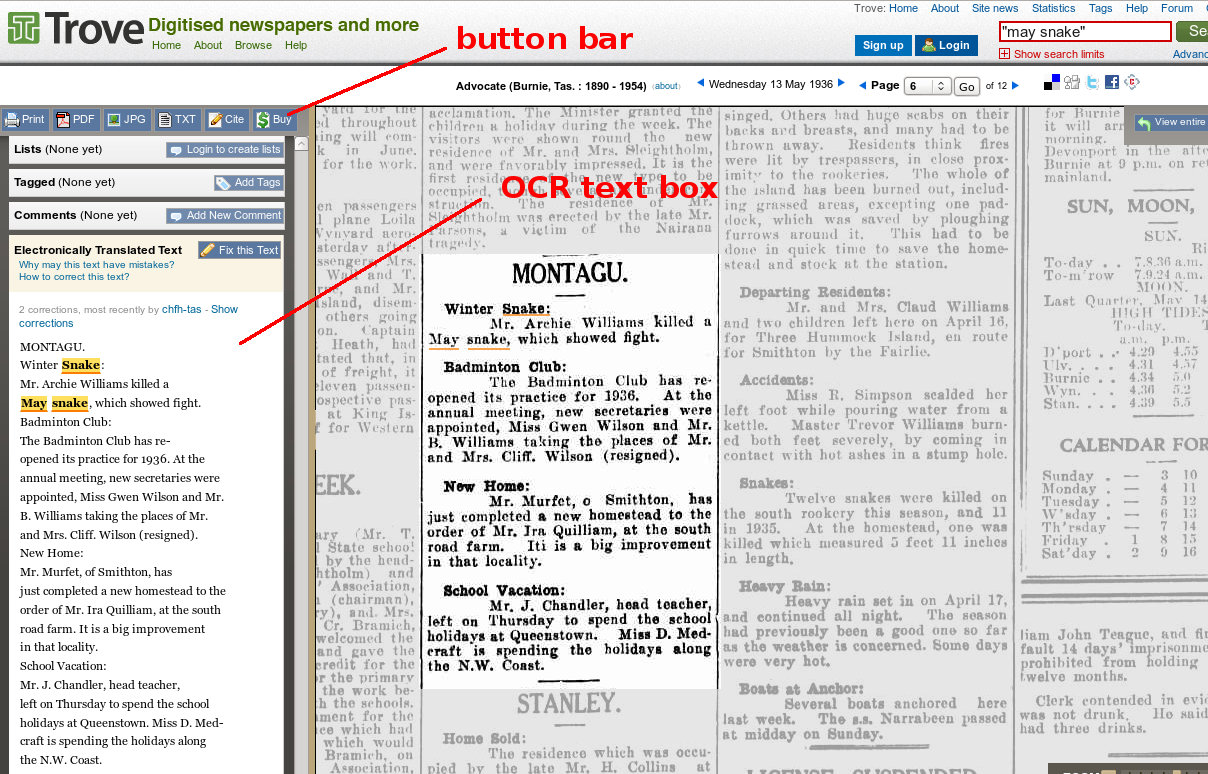
Click this or other images in this article for full size
If you're doing genealogical or historical research with Trove you might want to keep a record of the articles you've found or edited. You can do this by clicking on the 'PDF' or 'JPG' buttons in the OCR panel and downloading a PDF or JPG file, annotated with the Trove URL for the article, and the newspaper name, date and page. You can also click on the 'Print' button to make a paper copy of an article image. Again, the printable image includes the URL and the newspaper name, date and page.
If you just want to capture the OCR text of an article, you can click on the 'TXT' button. A pop-up window appears

from which you can copy and paste the latest version of the OCR text into your own document. However, you have to add the newspaper name, date and page and the Trove URL yourself.
I wrote a script which adds these items automatically to the OCR text together with today's date. The script appends the whole shebang to an ever-growing text record of my newspaper searches. The script also preserves the layout of the original newspaper article:

Below I explain how the script works. In a nutshell, the script downloads the source code for the webpage on which the article is displayed. GNU/Linux text tools are then used to extract the OCR text and other items from the page code, and to arrange them in the way I like. After appending the final arrangement to my Trove text record, the downloaded page code is deleted. To operate the script while viewing a Trove page I do three keyboard entries, one after the other:
Alt+d selects the Web address (in the address bar) of the page I'm viewing. This keyboard shortcut works in both Firefox/Iceweasel and Chrome/Chromium (also Microsoft's Internet Explorer).
Ctrl+c copies the text of the Web address to the clipboard (the secondary clipboard on X window systems).
Super+y is the keyboard shortcut I've assigned to the launching of my Trove script.
Here's the script:
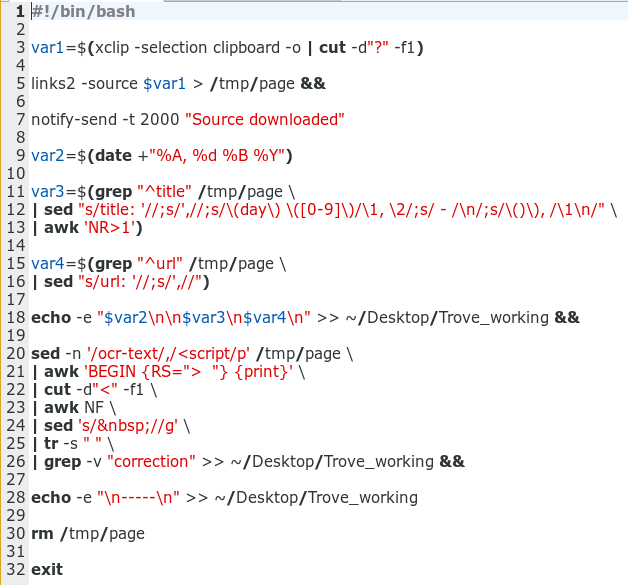
and now for the long-winded explanation...
Lines 3-7: get the page source code
After Alt+d and Ctrl+c, the page URL is on the secondary (Ctrl+c) clipboard. To get it off the clipboard I use the xclip utility:
xclip -selection clipboard -o
The URL for a search page can be long and very ugly. Here's the URL for the page in the screenshot above:

All we actually need from this is the Trove folder address and the article's identifying number, in this case http://trove.nla.gov.au/ndp/del/article/91792494. We can trim off the trailing search bits in the address by telling the cut command that the string from the clipboard is broken into fields by the ? character, and we want just the first field:
cut -d"?" -f1
The trimmed URL is then passed as a variable to the links command-line Web browser. links is told with the -source option to just download the page source code and send that to a temporary file, /tmp/page. The trailing double ampersand tells the script to wait until that job is done before doing anything else:
links2 -source $var1 > /tmp/page &&
When the page code has been entered in /tmp/page, a notification is sent to my desktop; the notification message disappears after 2 seconds:
notify-send -t 2000 "Source downloaded"
It usually takes 3-5 seconds for the page code download.
Lines 9-18: prepare the header lines
The first item for my article header is today's date, stored as a variable in my preferred format:
var2=$(date +"%A, %d %B %Y")
The rest of the script operates on the downloaded page code. The second header item is based on a line beginning with title, buried deep in the page code . In the code it looks like this:

The first step is to find the line using grep:
grep "^title" /tmp/page
Next, I pass the line to sed for some reformatting jobs. Note that the sed command here is enclosed in double quotes to allow sed to operate on single ones.
s/title: '// — delete the intial string title: '
s/',// — delete the ', at the end of the line
s/\(day\) \([0-9]\)/\1, \2/ — look for the string day[space] followed by a number, and separate these with a comma
s/ - /\n/ — There's a small trick here. I want to replace the string [space]-[space] between the article title and the newspaper name with a newline. The sed command does that, but because I haven't add a g for global to the command, sed only replaces the first instance of [space]-[space], and not the instance in 1890 - 1954.
s/\()\), /\1\n/ — An ugly-looking 'picket-fence' command, but in fact simple. It replaces the ),[space] characters before the date with ) and a newline.
Here you can see how the sed commands work, in sequence:

The last command uses AWK to remove the article title. The title isn't needed in the header because it also appears in the OCR text (see below):
awk 'NR>1'
The finished two lines from the 'title' string are stored in a variable.
Next, grep is used to find the URL line in the page code:

Please note that this is not the same as the URL of the page I was viewing. The URL found here is Trove's 'persistent identifier' for the article. The URL line is tidied as above and stored in a variable:
var4=$(grep "^url" /tmp/page | sed "s/url: '//;s/',//")
The last step in preparing the header is to pass the variables to echo for building with my preferred newline spacing, and to append the header to my Trove text file on my desktop:
echo -e "$var2\n\n$var3\n$var4\n" >> ~/Desktop/Trove_working &&
Lines 20-26: prepare the OCR text
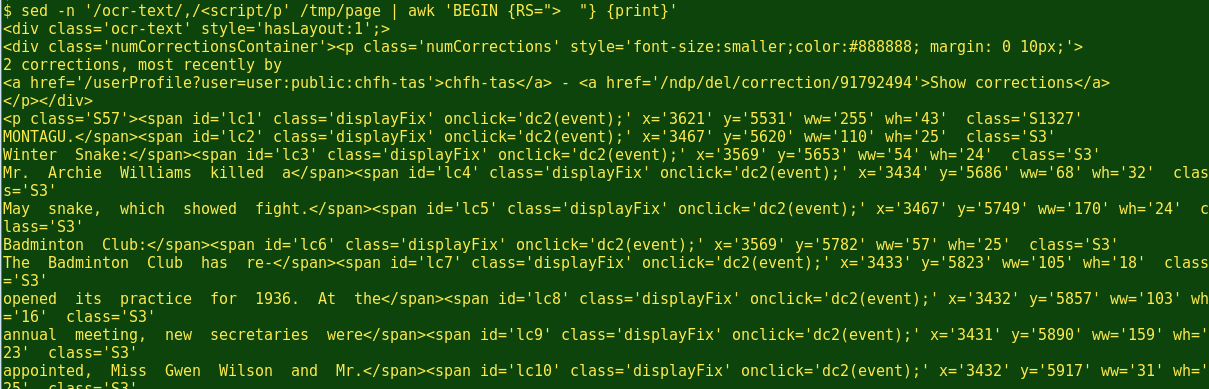
Here's how the OCR text looks in the page code:

It's located in a <div> classed as 'ocr-text' and it's followed by an edit-mode script. To grab the OCR text from the page code, I use sed to print all the text from the line with 'ocr-text' to the line with '<script', inclusive. (The bracket before 'script' is there in case the OCR text also contains the word 'script'.)
sed -n '/ocr-text/,/<script/p' /tmp/page
Now to get the text out... If you look closely at the page code you'll notice that each of the OCR'ed lines is preceded by a > and two spaces. If we use that combination as a record separator, AWK will neatly separate the lines:
awk 'BEGIN {RS="> "} {print}'
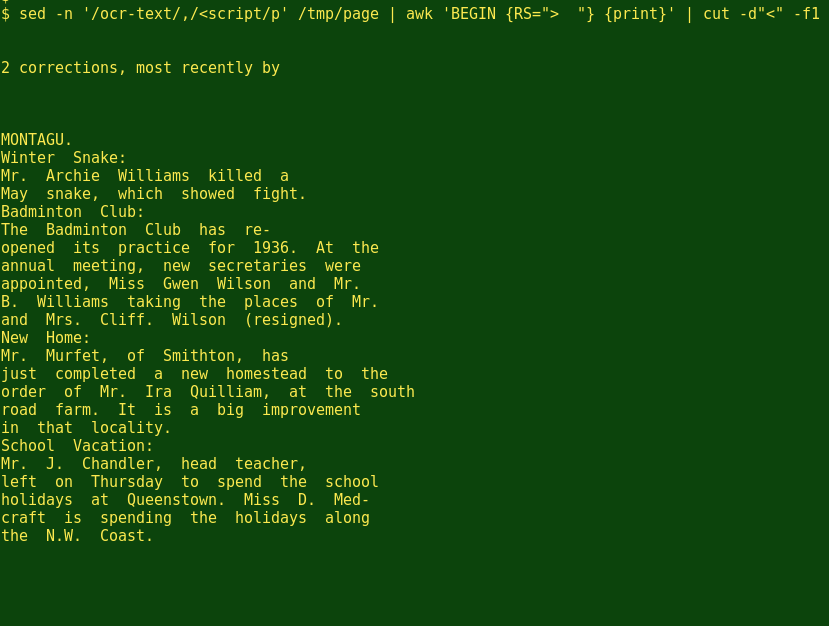
The cut command now looks for the first field in each line, with the field delimiter set to <. This command deletes any line beginning with <, and removes the markup at the end of the OCR lines:
cut -d"<" -f1
The last four commands use AWK to delete any blank lines, sed to delete any stray non-breaking spaces ( ), tr with the 'squeeze' option -s to reduce any multiple whitespaces to a single whitespace, and grep with the -v (invert search) option to find all lines not containing the word 'correction':
awk NF | sed 's/ //g | 'tr -s " " | grep -v "correction"
The cleaned-up OCR text is then appended to my Trove text file.
Lines 28-31: Finishing
The echo command is used next to append spacer lines and the separator '-----' to the Trove text file, ready for the next article in my Trove searches (see the third image, above):
echo -e "\n-----\n" >> ~/Desktop/Trove_working
Finally, the temporary file with the page source code is deleted and the script exits.
Although the script works fine and has been very useful in my Trove newspaper searches, it depends strictly on the current layout of Trove Web pages. If the National Library of Australia changes the way it codes its newspaper pages, I'll have to modify my script. (Not a problem for a keen shell-scripting hobbyist, though...)