
Keeping emails as text files: 2 scripts
By Bob Mesibov, published 28/10/2015 in Tutorials
Most people store and organise their personal emails as individual files (messages) in folders. Those folders might be on a webmail company's servers, or in a mail client program on the user's personal computer. In both cases the emails are probably in a special email format.
I'm horribly old-fashioned. I store my emails in plain text files, one long file for each correspondent, in chronological order. To make this easier I use the two shell scripts described in this article.
Correspondent files
My emails are downloaded to Sylpheed email client. I have Sylpheed set up so it displays From, To, Subject and Date fields in the message preview pane. To store an email in a correspondent file, I highlight the headers and text as shown (not a real message):
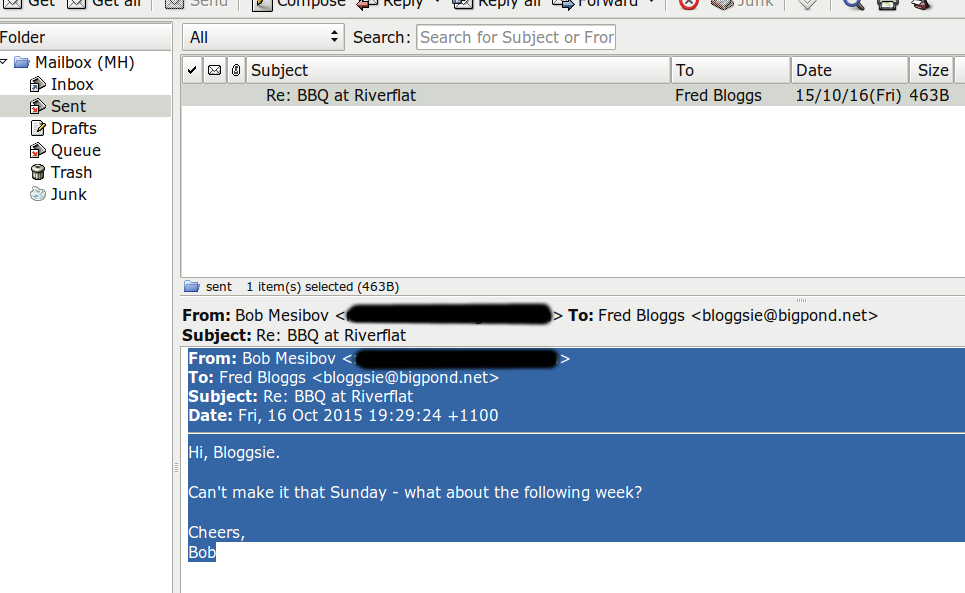
then use a keyboard shortcut to launch the 'appender' script:
#!/bin/bash
mailfile=$(yad --file --center --width=600 --height=400 --filename=/home/bob/Correspondence/Active/)
echo -e "\n\n-----\n" >> "$mailfile"
xclip -o >> "$mailfile"
yad --timeout=1 --geometry=300x50+1550+500 --undecorated --no-buttons \
--text="<b>Mail added to</b>\n<span color=\"#0000ff\"><b>$(basename "$mailfile")</b></span>" \
--text-align=center
exit 0A YAD file-chooser dialog lets me select a correspondent file. The script then uses echo to append a blank line, a separator line (5 hyphens in a row) and a newline to the end of the selected correspondent file. The xclip utility pastes the highlighted text:

and YAD posts a notification to my desktop for 1 second, just to check that the message went into the correct correspondent file:
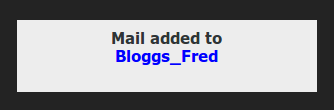
The headers+text are still on the X clipboard, so I can relaunch the script to add the message to another correspondent file, such as someone cc'ed in the email.
Searching the emails
I have about 120 text files in my active correspondents folder, and another 200 files in the inactive folder. To search for key words and phrases through the whole archive, I use this 'emails' script in a terminal:
#!/bin/bash
cd /home/bob/Correspondence
grep --color=always -r -n -i "$1" > /tmp/search
if [[ $? -ne 0 ]]; then
echo "Search string not found in email files"
rm /tmp/search
exit 0
else
echo -e "\nFound $(wc -l < /tmp/search) lines with \e[1;31m$1\e[0m:"
while read line; do
FILE=$(echo "$line" | cut -d: -f1 | sed 's/[^[:print:]]//g; s/\[35m\[K//; s/\[m\[K\[36m\[K//')
PLACE=$(echo "$line" | cut -d: -f2 | sed 's/[^[:print:]]//g; s/\[m\[K\[32m\[K//; s/\[m\[K\[36m\[K//')
TEXT=$(echo "$line" | cut -d: -f3-)
awk -v fil="$FILE" -v place="$PLACE" -v text="$TEXT" \
'NR < place && $0 ~ /Date:/ {x=$0} \
END {print "\n---\n\nFile: "fil; print x; print "Line: "place; print "\t"text}' $FILE
done < /tmp/search
fi
rm /tmp/search
exit 0Here's an example of a search:
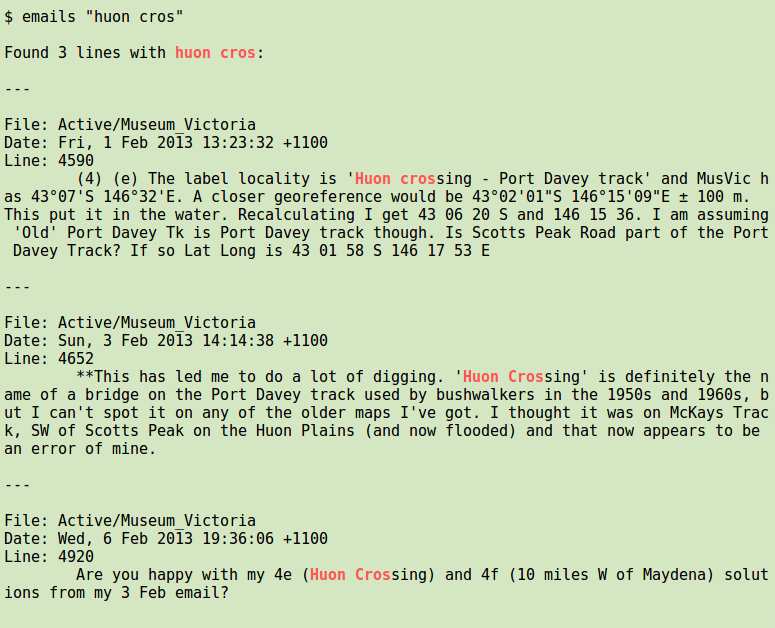
The searching is done with grep with 4 options. '--color=always' means that the default red highlighting of the searched-for string gets carried through to the final output. The '-r' option searches recursively through all files in my 'Correspondence' folder, '-i' makes the search case-insensitive and '-n' delivers the line number where the searched-for string appears. All successful searches are sent to a temp file:

If the string isn't found, the script echoes that result, deletes the blank temp file and exits. If the search is successful, the script echoes the number of lines found with the string.
A while loop next works through the temp file line by line, first extracting the file path, line number and line as variables. The complicated-looking sed commands remove the coloring with which grep highlights the file path and line number.
An AWK command then goes through the file specified by the file path, looking for the 'Date' header line before the line number containing the found string. That 'Date' line is stored as a variable and added to the final printing-out, which also includes newlines and a 3-hyphen separator to space out the found strings and their 'metadata'.
The script then deletes the temp file and exits. My AWK command isn't the most efficient way to grab the 'Date' line before each found string, but all my correspondent files are less than 100 000 lines, and AWK can whiz through those in an eyeblink.
Please note that none of my correspondent files have names containing spaces!