
How to garble
By Bob Mesibov, published 20/02/2015 in Tutorials
In 2003 a strange paragraph made the rounds on email. It read:
Aoccdrnig to rscheearch at an Elingsh uinervtisy, it deosn't mttaer in waht oredr
the ltteers in a wrod are, olny taht the frist and lsat ltteres are at the rghit pcleas.
The rset can be a toatl mses and you can sitll raed it wouthit a porbelm.
Tihs is bcuseae we do not raed ervey lteter by ilstef, but the wrod as a wlohe.
That 'research at an English university' part is a little dubious, but programmers had fun with the garbling principle. Jamie Zawinski wrote a Perl script to do it, with a licence text beginning Premssioin to use, cpoy, mdoify, drusbiitte, and slel this stafowre.... Steve Sachs set up a webpage for online garbling with an AWK script in CGI, and Clément Pit-Claudel even wrote code to ungarble garbled text.
Just for fun, I had a go at writing a garbler script using only BASH tools and basic GNU/Linux utilities — no sed or AWK. In this article I explain how the script works and point out its limitations. I'm only an amateur coder, and there are almost certainly other — and better — ways to do the same job!
Overview and starting off
The script converts a piece of text into a list of its component words, then does the garbling on each word separately, then reassembles the garbled words in the order they appeared in the starting text. Punctuation is a separate problem and I deal with it last in this demo.
I run the script on the command line, entering the command 'garbler' and following that with the text to be garbled, in double quotes:

The first job is to convert the spaces between words into newlines, to make a word list. I use the tr command to convert, and in the script (below) I echo and pipe the text to tr as the command argument $1. Here's that step with the full text echoed:

BASH string functions
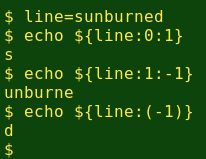
Each word in the list needs to have its first and last letters preserved, while the remaining letters get shuffled. BASH has string functions which do the word dissections very nicely. The function ${line:0:1} grabs the first character of the variable line, ${line:1:-1} extracts everything between the first and last character, and ${line:(-1)} dissects out the last character. (Another syntax for last character extraction is ${line: -1}, with a space between the colon and the -1. To me, ${line:(-1)} is clearer.):
Garbling
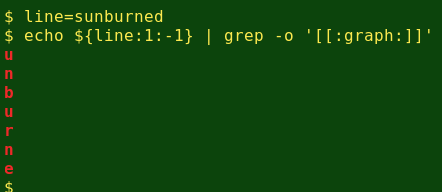
To shuffle the middle of a word, I first convert that string into a list of its component letters with the grep command and its -o option, telling grep to search the string for visible characters (POSIX character class [:graph:]):
Next, I pipe that list to the shuf command, which shuffles the list of letters. (See this article for more on shuf.)
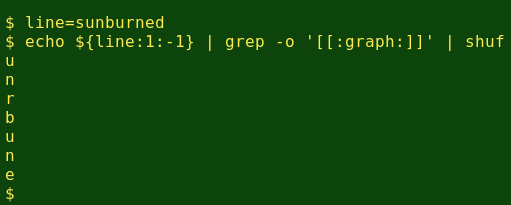
To reassemble the letters into a middle-of-word string, I use the paste command, telling it with the -s option to make the list into a single line, and with -d '' to use nothing at all as a delimiter between letters:

Basic processing
I pipe the list of starting words to a while loop to work through and garble the words one by one:
echo $1 | tr ' ' '\n' \
while read line; do
echo -n ${line:0:1}
echo -n $(echo ${line:1:-1} | grep -o '[[:graph:]]' | shuf | paste -s -d '')
echo ${line:(-1)}
doneThe loop reads each word in the list and does three things. First it echoes the word's first letter, then it echos the garbling of the word's middle, then it echoes the last letter. Note the -n option in the first two echoings, which stops echo from adding a new line afterwards. Without the -n option, the three separate jobs would appear on three separate lines of output. I could avoid the use of -n by concatenating the three echos:

but I've kept this layout to make the code clearer (it gets more complicated, below).
The final step in processing is to reassemble the starting text, and paste is again my friend, this time with a single space as delimiter:

Tweak 1: word length
There's no point in asking the script to garble a one-letter word (a), or a two-letter word (an) or a three-letter word (the). It makes sense to filter out the short words before processing, and that's easily done with an if/else construction, like this:
echo $1 | tr ' ' '\n' \
| while read line; do
if [WORD IS LONGER THAN 3 LETTERS]; then
echo -n ${line:0:1}
echo -n $(echo ${line:1:-1} | grep -o '[[:graph:]]' | shuf | paste -s -d '')
echo ${line:(-1)}
else echo $line
fi
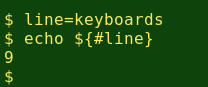
done | paste -s -d ' 'Here the 'else' instruction is just to echo the 1-, 2- or 3-letter word as is. The if test is done with another BASH string function, ${#line}, which counts characters in a string:
and here's the test in place ( -gt is greater than):
echo $1 | tr ' ' '\n' \
| while read line; do
if [[ ${#line} -gt 3 ]]; then
echo -n ${line:0:1}
echo -n $(echo ${line:1:-1} | grep -o '[[:graph:]]' | shuf | paste -s -d '')
echo ${line:(-1)}
else echo $line
fi
done | paste -s -d ' 'Tweak 2: punctuation
Full stops and commas will be processed like any other characters by the BASH string function ${line:(-1)}. If a comma comes at the end of a word, the script will put the comma back at the end and scramble the middle+end letters of the word, which isn't what I want.
To get around this problem, I add another if/else construction and test to see if the last character in a word is a punctuation character (POSIX character class [:punct:]). If it is, I use another form of the BASH string tool to get the second to next-to-last characters rather than the second to the last:
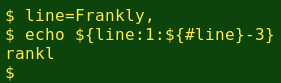
I then add back the last two characters (${line:(-2)}), namely the last letter and the following punctuation mark.
The final script looks like this:
#!/bin/bash
echo $1 | tr ' ' '\n' \
| while read line; do
if [[ ${#line} -gt 3 ]]; then
echo -n ${line:0:1}
if [[ ${line:(-1)} =~ [[:punct:]] ]]; then
echo -n $(echo ${line:1:${#line}-3} | grep -o '[[:graph:]]' | shuf | paste -s -d '')
echo ${line:(-2)}
else echo -n $(echo ${line:1:-1} | grep -o '[[:graph:]]' | shuf | paste -s -d '')
echo ${line:(-1)}
fi
else echo $line
fi
done | paste -s -d ' '
exitLimitations
The script won't give good results if the starting text has extra spaces or internal punctuation, as in it's and won't. Extra spaces could be removed by pre-processing the text with the tr command and its 'squeeze' option (tr -s ' '). However, I can't see how to cater for internal punctuation in a simple and general way.
Note also that the shuf step might return a word with its letters in their ungarbled order, because that's one of the possible orders in which the middle characters can be shuffled. This apparent non-shuffling is going to be more likely for shorter words. It would be possible to force a garbled result, by repeating the garbling on a word in the word list if the starting and finishing orders were the same.
But the script works well enough for me and does pretty much what it's supposed to do!
