
AWK and a rainfall time series - Part 1
By Bob Mesibov, published 15/05/2017 in Tutorials
AWK is my tool of choice for processing plain-text data, so when I wanted to look closely at daily rainfall data for my home town, I fired up a terminal. In this two-part article I explain how the rainfall data were beaten into shape, mainly with AWK, so I could do my analysis. The commands shown here are specific to the rainfall study, but I'm hoping Linux Rain readers will find them useful and adaptable to other data-processing jobs.
Rainfall data for recording stations around Australia are freely available at the Bureau of Meteorology's Climate Data Online website. From there I downloaded all years of daily rainfall totals for Ulverstone, Tasmania (rainfall station 091102) as a ZIP file and extracted the CSV containing the data. The Bureau's CSVs are uncomplicated (no commas embedded in data items) and have the fields:
- Product code
- Bureau of Meteorology station number
- Year
- Month
- Day
- Rainfall amount (millimetres) (here called total)
- Period over which rainfall was measured (days) (here called period)
- Quality
Preparing the data
I prefer tab-separated data and for my purposes the header line and the first two and last fields aren't needed, so I generate the working table rain0 with
tail -n +2 IDCJAC0009_091102_1800_Data.csv | tr ',' '\t' | cut -f3-7 > rain0The table rain0 now has five fields: year (field 1), month (2), day (3), total (4) and period (5). The table is in chronological order and lists all days from 1 January 1889 to 31 March 2017:
The data might look usable as-is, but they're not. For the analysis I'll be doing, I need to fill in missing data, as described below. I also need to know the period for all days on which some value is given for total. However, for thousands of days with a recorded total (field 4 in rain0 not blank), the period field is blank:
awk -F"\t" '$4 != "" && $5 == ""' rain0 | wc -l
All of those days, it turns out, have zero recorded rainfall:
awk -F"\t" '$4 != "" && $5 == "" {print $4}' rain0 | sort | uniq -c

I'm going to assume that those are 1-day totals, because that makes sense, and also because the 60 days with "0.0" totals and a period entry are 1-day totals:
awk -F"\t" '$4 == "0.0" && $5 != "" {print $5}' rain0 | sort | uniq -c
So, I edit rain0 with AWK to fill "1" into blank period fields where the total is "0.0", generating a new working file rain1:
awk 'BEGIN {FS=OFS="\t"} $4 == "0.0" && $5 == "" {$5=1} 1' rain0 > rain1which fixes the problem:

Note that I specified both the input and output field separator as a tab character in that editing command. This was new-file building, not just file filtering, so AWK needed to be told that the new file was to have tab-separated fields.
Another data issue is that there's one record in the Bureau's table with nothing in total, but with a periodentry nevertheless:
awk -F"\t" '$4 == "" && $5 != "" {print NR": "$0}' rain1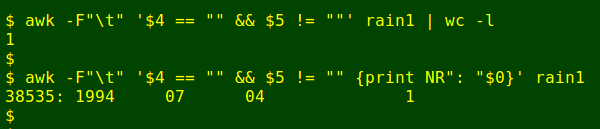
That's odd, but I'll assume that total wasn't actually recorded on that day (4 July 1994, line 38535 in rain1) and I'll delete the final "1" with sed:
sed -i '38535s/1$//' rain1Missing data
If there are days with total missing, then monthly or yearly summaries and other analyses will be flawed. To find out how many days are missing a rainfall total, I use AWK and wc to count the records that have nothing in field 4.
awk -F"\t" '$4 == ""' rain1 | wc -l
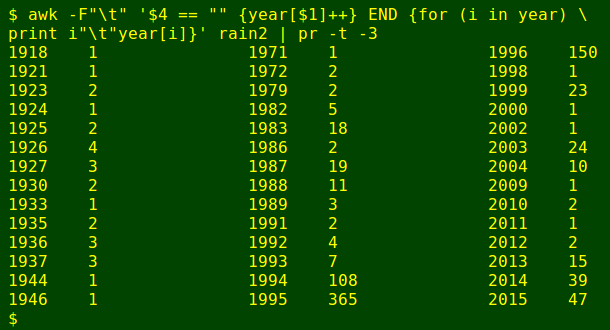
Oops. Nearly 20% of the days in the 127-year record don't have a rainfall total. Below, AWK looks for records with missing data and builds an array ("year") to count those days by year (field 1). When finished, it prints the year and the number of days with rainfall missing in that year, tab-separated. I send the result to pr to make three columns for easier viewing:
awk -F"\t" '$4 == "" {year[$1]++} END {for (i in year) print i"\t"year[i]}' rain1 | pr -t -3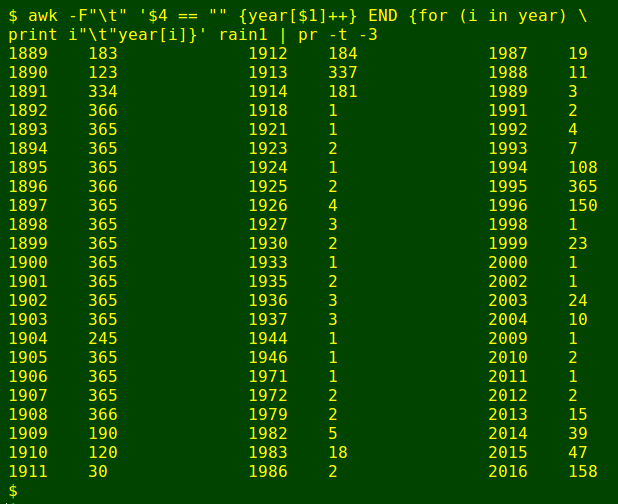
Hmmm. Maybe I'll just look at the 100 years from 1916 to 2015, inclusive. I get AWK to select records in that year range as the new working file rain2:
awk -F"\t" '$1 >= 1916 && $1 <= 2015' rain1 > rain2
My working file rain2 has 36525 days, and the number of "missing data" days is down from 8821 to 893, most of which are in the years 1994-1996:
There are gaps, and gaps
To fill the missing-data gaps, I can use a time-honoured meteorologist's fudge. I'll look up the rainfall total for a nearby station or stations with a similar weather pattern on each missing-data day, and use the nearby-station totals after adjusting them for the expected difference between the nearby stations and the one with the missing data. This is called "infilling" by meteorologists and hydrologists. It's really just a SWAG.
However, there's another wrinkle in the analysis. Daily rainfall total could be missing for a range of reasons. Maybe the rainfall recording apparatus was out of service, or the human rainfall recorder was away on holidays, or maybe no rain fell for a while and the recorder forgot to enter "0.0" in the record for those days. If the rainfall gauge was open or the apparatus functioning in the missing-data gap, the record might actually show the accumulated total for several days after a run of missing data. Accumulated totals are solid data for the missing-data station and should be the basis for any infilling.
Here's my plan. First I'll "backfill" gaps ending in accumulated totals, then I'll infill the remaining 1-day gaps, in both cases using data from a nearby station or stations:

Before extracting records for backfilling, I'll just check to make sure that the accumulated totals are well-behaved. In a well-behaved list, a total from a period of 4 days would be preceded by 3 days missing a total. To check this I'll use the AWK command:
awk -F"\t" '$4 == "" {blanks++; next} $5 > 1 {print blanks,$5} {blanks = 0}' rain2 | sort -n | uniq -cAWK works through rain2 line by line. If the line is missing a total, it starts a counter variable "blanks" and moves to the next line. (Incrementing variables in AWK start with a count of 1.) If that next line is also missing a total, the counter increments by 1. If the line instead has a total, AWK moves to the second part of the command, which checks the value of period. If that value is greater than 1, indicating an accumulated total, AWK prints the count of preceding missing-data lines, followed by the period. It then resets the counter to zero, and continues line-by-line processing. The output is sorted and tallied with uniq -c.
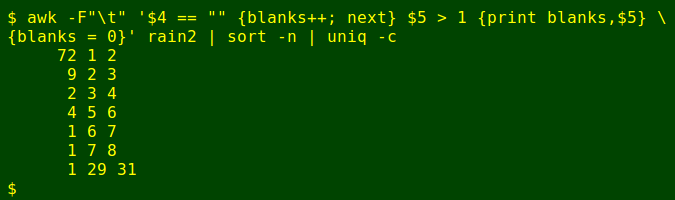
Ugh, another data issue. period should be just one more than the number of preceding missing-data lines. The "29, 31" turns out to be a Bureau confusion. That 31-day period ends on 31 May 1996, but there's a rainfall total given in rain2 for 1 May 1996, 30 days earlier. I correct this with sed again, changing the period on 31 May 1996 (line 29372 in rain2) from 31 to 30 days:
sed -i '29372s/31$/30/' rain2and re-run the tallying command:
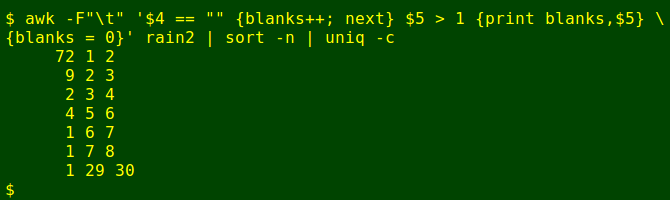
That's better.
Matching stations
The three nearest stations to Ulverstone (Knights Road) with long-term daily rainfall records are Burnie (Round Hill, 22 km to the west), Latrobe (Coal Hill Road, 22 km to the southeast) and Northdown (Hamley, 27 km to the east). I downloaded all-years daily rainfall records for the three stations and processed them as described for the Ulverstone data:
- trimmed the data tables to the five fields year (field 1), month (2), day (3), total (4) and period (of accumulation) (5)
- filled in '1' as the period for records with no period entry and "0.0" in the total field
- checked to be sure there were no records with a period entry but no total entry
- selected records from 1916 to 2015, inclusive
The AWK-processed Burnie file burnie2 begins on 29 August 1944, while latrobe2 and northdown2 have rainfall records from 1 January 1916 to 31 December 2015 but are entirely missing some days. For the next step in infilling missing Ulverstone data I need to make the list of days the same in all four files. To do this I first make a chronological "dummy" file from Ulverstone's rain2 file. It has all the days from 1 January 1916 to 31 December 2015 but no total or period entries:
awk 'BEGIN {FS=OFS="\t"} {$4=""; $5=""} 1' rain2 > dummy
Next I use a few command-line utilities, here demonstrated with the Ulverstone vs Burnie data:
comm -3 <(cut -f1-3 dummy | sort) <(cut -f1-3 burnie2) > burnie2_gaps
grep -f burnie2_gaps dummy | cat - burnie2 | sort -n -k1 -k2 -k3 > burnie_cIn the first command, the first three fields (year, month, day) are cut from dummy and burnie2, sorted and passed to comm with option "-3", which means "suppress lines common to the two files". This gives me a list of dates missing from burnie2, which I save as burnie2_gaps.
In the next command, grep looks in dummy for the dates listed in burnie2_gaps. Those lines from dummy (with their blank total and period fields) are then added to burnie2 with cat, and the result sorted by year, month and day and saved as burnie_c.
Having done this for the Latrobe and Northdown data as well, I paste the total and period fields for the three nearby stations next to the corresponding dates in the Ulverstone file, creating the combined table topless_four_towns. I then add a header line to explain what the fields are, generating four_towns. In the screenshot below, I've scrunched up the spacing a little with the tabs command to make the image smaller.
paste rain2 <(cut -f4,5 burnie_c) <(cut -f4,5 latrobe_c) <(cut -f4,5 northdown_c) > topless_four_towns
echo -e "Year\tMonth\tDay\tUlvT\tUlvP\tBurT\tBurP\tLatT\tLatP\tNorT\tNorP" | cat - topless_four_towns > four_towns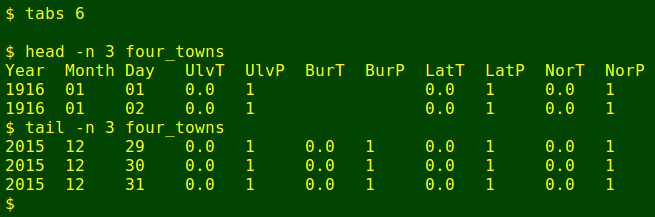
Getting the adjustment factors
Meteorologists have sophisticated statistical ways to do their infilling of missing data. My method is very simple. I just add up the total rainfall for Ulverstone and for a nearby station on days when either station recorded a non-zero 1-day fall, then divide the Ulverstone total by the nearby-station total. That's my adjustment factor for estimating Ulverstone rainfall.
Check the image above to understand what fields are selected in the following Ulverstone-Burnie example:
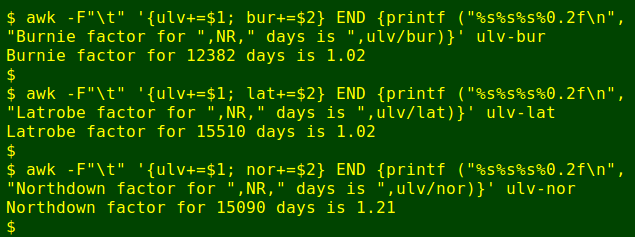
awk -F"\t" '($4 != "0.0" || $6 != "0.0") && $5 == 1 && $7 == 1' four_towns | cut -f4,6 > ulv-bur
awk -F"\t" '{ulv+=$1; bur+=$2} END {printf ("%s%s%s%0.2f\n", "Burnie factor for ",NR," days is ",ulv/bur)}' ulv-burThe first command selects the relevant days from four_towns and cuts out just the rainfall totals, saving these in ulv-bur.
The second command creates the variables "ulv" and "bur", in which the respective rainfalls in ulv-bur are progressively added up. After AWK reaches the last line in ulv-bur, it prints a message stating the number of days used (same as number of lines = NR, in ulv-bur) and the ratio of Ulverstone to Burnie totals to two decimal places (using the printf format "%0.2f" for floating-point arithmetic).
These adjustment factors will be handy for infilling rainfall totals on missing-data days outside an accumulation period. For more on infilling and backfilling, see part 2 of this article.
(To be continued)