A script to find empty fields in a table
By Bob Mesibov, published 16/07/2017 in Tutorials
It's pretty easy to see which fields are empty in the tab-separated table demo (below). The 2nd and 4th field, Col2 and Col4, have no visible characters at all in the rows below the header line:
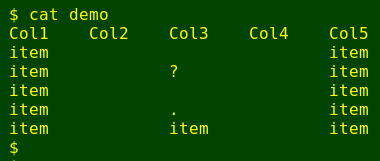
That was simple, but what if the table is huge, with lots of fields and records? Eyeballing for fields without visible characters would be tedious, and calling a non-empty field an empty one would be an easy mistake to make. This article explains a script I wrote to automate the job of finding and recording empty fields in very big tables.
Overall strategy
The most straightforward approach (it seemed to me) would be to process one field at a time from the table and test it. If the test showed that the field was empty, I'd print the field's label (from the header line). If the field contained something visible, I'd ignore the field. In pseudo-code, I'd do this:
for ((i=1;i<={total number of fields};i++)); do \
cut -f "$i" {the table} | {test the field's contents; if no visible characters found, print field name]; \
doneThe result would be a list of field names for the empty fields. [Note that the cut command understands the tab character as field separator by default, and I always work with tab-separated tables.] But how to get the total number of fields before processing?
I opted to use this code, similar to something I used before when scripting a table transposer:
totf=$(($(head -n 1 {the table} | grep -o $'\t' | wc -l)+1))This expression grabs the header line from the table with head, then extracts the tab characters from the line with grep and lists them. The wc command counts lines in that list, and adding 1 to that count gives me the total number of fields in the table.
To generalise the empty-field-finding, I'll write a BASH script called "empties", and pass a table's name to the command as its first argument, as in empties demo. The pseudo-script for "empties" will look like this:
#!/bin/bash
totf=$(($(head -n 1 "$1" | grep -o $'\t' | wc -l)+1))
for ((i=1;i<="$totf";i++)); do \
cut -f "$i" "$1" | {test the field's contents; if no visible characters found, print field name}; \
done
exitAWK steps in
An isolated field from the table is just a list of lines, and AWK is an ideal tool for testing an isolated field line by line to see if the field is empty. A first attempt might look like this in AWK pseudo-code:
awk 'NR==1 {label=$0} \
NR>1 [[test to see if rows are empty; if all rows empty, print "label"]]Here AWK takes the field name from the header line (NR==1) and saves the field name in the variable "label". It then works through the remainder of the field row by row. But this is pretty inefficient. If the first row after the header has visible characters, why not stop the testing process there and then, and move on to the next field in the for loop? A better strategy would be:
awk 'NR==1 {label=$0} \
NR>1 [[if row is non-empty, quit, otherwise continue; if all rows are empty, print "label"]]In other words, if AWK processes all the rows without quitting, then the field must be empty. In the script, this might look like
#!/bin/bash
totf=$(($(head -n 1 "$1" | grep -o $'\t' | wc -l)+1))
for ((i=1;i<="$totf";i++)); do \
cut -f "$i" "$1" | awk 'NR==1 {label=$0} \
NR>1 && $0 != "" {f=1; exit} \
END {if (!f) print label}';
donewhere the test $0 != "" means the row is not empty. When AWK finds its first non-empty row, it sets a flag "f" to true (1) and stops processing lines. AWK then moves to the END statement. If a flag has been set, nothing happens. If no flag was set ("!f"), meaning all the rows were empty, AWK prints the field name.
What does "empty" mean?
Unfortunately, this doesn't work if there are invisible whitespaces in the row, because AWK sees those whitespaces as characters:

What looks empty to you and me, because there's no visible data, isn't empty to AWK. The workaround is to use a different test for non-emptiness, based on the POSIX character class [:graph:]. That class includes just the visible characters (letters, numbers and punctuation). The test uses AWK's "gsub" function:

Here "gsub" looks for matches to the [:graph:] character class, replaces each match with a blank ("") and returns the number of replacements it's made. If no replacements are made, there are no visible characters and the return is null. If the return is greater than zero, there are visible characters in the row.
The script now looks like this:
#!/bin/bash
totf=$(($(head -n 1 "$1" | grep -o $'\t' | wc -l)+1))
for ((i=1;i<="$totf";i++)); do \
cut -f "$i" "$1" | awk 'NR==1 {label=$0} \
NR>1 && gsub(/[[:graph:]]/,"")>0 {f=1; exit} \
END {if (!f) print label}';
done
exitSome improvements
I'd also like the script to output the field number of each empty field, since that could be useful in other commands (see below). AWK can store that field number in a variable ("fnum"):
#!/bin/bash
totf=$(($(head -n 1 "$1" | grep -o $'\t' | wc -l)+1))
for ((i=1;i<="$totf";i++)); do \
cut -f "$i" "$1" | awk -v fnum="$i" 'NR==1 {label=$0} \
NR>1 && gsub(/[[:graph:]]/,"")>0 {f=1; exit} \
END {if (!f) print fnum ":" label}';
done
exitThe next improvement to the script would be a report on how many empty fields were found. A simple way to do this is to send the results to a file as well as to standard output using tee. The number of lines in that saved file can be reported with the wc -l command:
#!/bin/bash
totf=$(($(head -n 1 "$1" | grep -o $'\t' | wc -l)+1))
for ((i=1;i<="$totf";i++)); do \
cut -f "$i" "$1" | awk -v fnum="$i" 'NR==1 {label=$0} \
NR>1 && gsub(/[[:graph:]]/,"")>0 {f=1; exit} \
END {if (!f) print fnum ":" label}';
done | tee "$1"_emptyfields
echo ""
echo "$(wc -l < "$1"_emptyfields) empty field(s) in "$1" table"
exit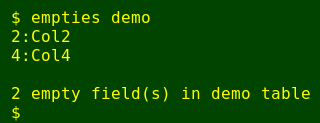
I'll try the script on a big table of Wandering Albatross occurrences from the Global Biodiversity Information Facility (GBIF). The file is called albatross and it has 235 fields and 53601 records:
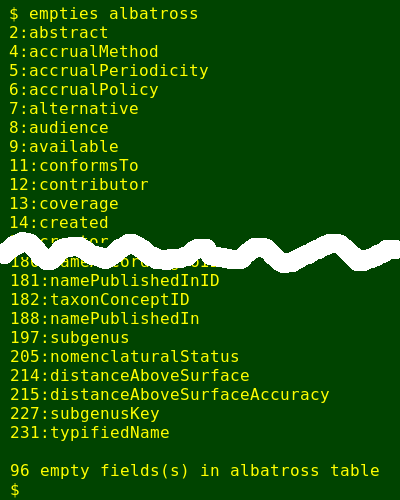
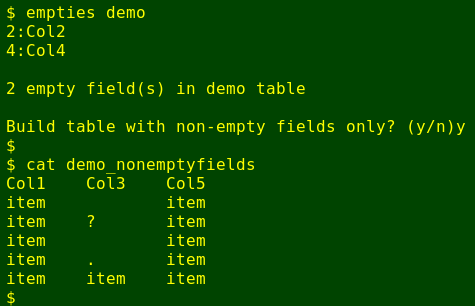
Works well, but there's yet another useful tweak to the script. From the "[filename]_emptyfields" file I can build a command to generate a new table with just the non-empty fields. To do this I first use cut to separate off those field numbers before the colon. I then paste the resulting list of field numbers into a single comma-separated string, and tell cut to get the complement of this list from the original table:
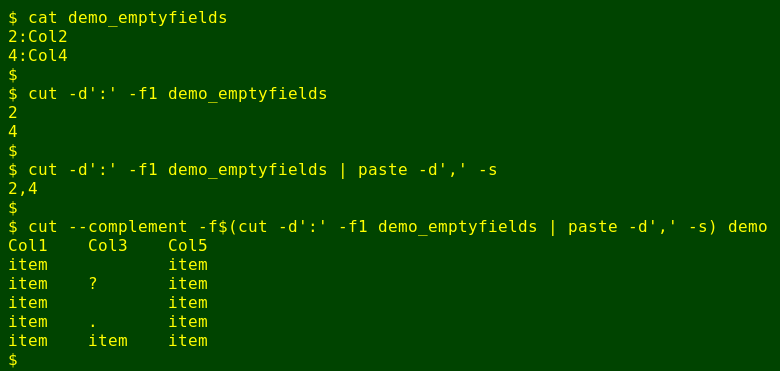
And I can make this an option in the script. Here's my working version of the script "empties":
#!/bin/bash
totf=$(($(head -n 1 "$1" | grep -o $'\t' | wc -l)+1))
for ((i=1;i<="$totf";i++)); do \
cut -f "$i" "$1" | awk -v fnum="$i" 'NR==1 {label=$0} \
NR>1 && gsub(/[[:graph:]]/,"")>0 {f=1; exit} \
END {if (!f) print fnum ":" label}';
done | tee "$1"_emptyfields
echo ""
echo "$(wc -l < "$1"_emptyfields) empty field(s) in "$1" table"
echo ""
read -p "Build table with non-empty fields only? (y/n)" foo
if [[ "$foo" == "y" ]]; then
cut --complement -f$(cut -d':' -f1 "$1"_emptyfields | paste -d',' -s) "$1" > "$1"_nonemptyfields
else
exit
fi
exit